
El reconocimiento automático de voz (ASR) ha recorrido un largo camino. Aunque fue inventado hace mucho tiempo, casi nunca fue utilizado por nadie. Sin embargo, el tiempo y la tecnología ahora han cambiado significativamente. La transcripción de audio ha evolucionado sustancialmente.
Tecnologías como AI (inteligencia artificial) han potenciado el proceso de traducción de audio a texto para obtener resultados rápidos y precisos. Como resultado, sus aplicaciones en el mundo real también han aumentado, con algunas aplicaciones populares como Tik Tok, Spotify y Zoom que integran el proceso en sus aplicaciones móviles.
Entonces, exploremos ASR y descubramos por qué es una de las tecnologías más populares en 2022.
¿Qué es voz a texto?
La voz a texto es una tecnología mejorada por IA que traduce el habla humana de una forma analógica a una digital. Además, la forma digital de los datos recopilados se transcribe a un formato de texto.
La voz a texto a menudo se confunde con el reconocimiento de voz, que es completamente diferente de este método. En el reconocimiento de voz, la atención se centra en identificar los patrones de voz de las personas, mientras que, en este método, el sistema trata de identificar las palabras que se pronuncian.
Nombres comunes de voz a texto
Esta tecnología avanzada de reconocimiento de voz también es popular y se la conoce con los nombres:
- Reconocimiento automático de voz (ASR)
- Reconocimiento de voz
- Reconocimiento de voz por computadora
- Transcripción de audio
- Lectura de pantalla
Comprender el funcionamiento del reconocimiento automático de voz
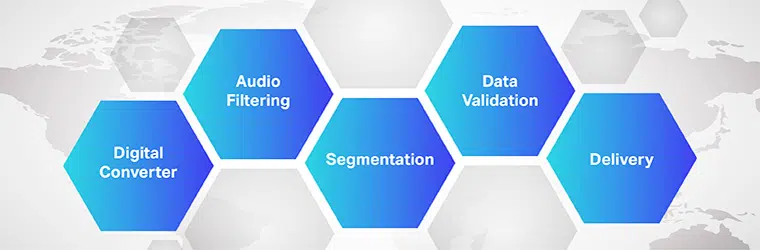
El funcionamiento del software de traducción de audio a texto es complejo e implica la implementación de múltiples pasos. Como sabemos, Speech-to-Text es un software exclusivo diseñado para convertir archivos de audio en un formato de texto editable; lo hace aprovechando el reconocimiento de voz.
Proceso
- Inicialmente, utilizando un convertidor de analógico a digital, un programa de computadora aplica algoritmos lingüísticos a los datos proporcionados para distinguir las vibraciones de las señales auditivas.
- A continuación, los sonidos relevantes se filtran midiendo las ondas sonoras.
- Además, los sonidos se distribuyen/segmentan en centésimas o milésimas de segundo y se comparan con fonemas (una unidad de sonido medible para diferenciar una palabra de otra).
- Los fonemas se ejecutan más a través de un modelo matemático para comparar los datos existentes con palabras, oraciones y frases conocidas.
- La salida es un archivo de texto o de audio basado en computadora.
[También lea: Una descripción completa del reconocimiento automático de voz]

¿Cuáles son los usos de voz a texto?
Hay múltiples usos de software de reconocimiento automático de voz, como
- Búsqueda de contenido: La mayoría de nosotros hemos pasado de escribir letras en nuestros teléfonos a presionar un botón para que el software reconozca nuestra voz y proporcione los resultados deseados.
- Servicio al Cliente: Los chatbots y los asistentes de IA que pueden guiar a los clientes a través de los pocos pasos iniciales del proceso se han vuelto comunes.
- Subtítulos en tiempo real: Con un mayor acceso global al contenido, los subtítulos en tiempo real se han convertido en un mercado destacado e importante, lo que impulsa el uso de ASR.
- Documentación electrónica: Varios departamentos de administración han comenzado a usar ASR para cumplir con los propósitos de documentación, atendiendo a una mayor velocidad y eficiencia.
¿Cuáles son los desafíos clave para el reconocimiento de voz?
anotación de audio aún no ha alcanzado el pináculo de su desarrollo. Todavía hay muchos desafíos que los ingenieros están tratando de contrarrestar para hacer que el sistema sea eficiente, como
- Ganar control sobre acentos y dialectos.
- Comprender el contexto de las oraciones habladas.
- Separación de ruidos de fondo para amplificar la calidad de entrada.
- Cambiar el código a diferentes idiomas para un procesamiento eficiente.
- Analizar las claves visuales utilizadas en el discurso en el caso de archivos de vídeo.
Transcripciones de audio y desarrollo de inteligencia artificial de voz a texto
El mayor desafío con el software de reconocimiento automático de voz es crear su salida con un 100 % de precisión. Como los datos sin procesar son dinámicos y no se puede aplicar un solo algoritmo, los datos se anotan para entrenar a la IA para que los entienda en el contexto adecuado.
Para llevar a cabo este proceso, se deben implementar tareas específicas, tales como:
 Reconocimiento de entidad nombrada (NER): NER es el proceso de identificar y segmentar diferentes entidades nombradas en categorías específicas.
Reconocimiento de entidad nombrada (NER): NER es el proceso de identificar y segmentar diferentes entidades nombradas en categorías específicas.- Análisis de opinión y tema: El software que utiliza varios algoritmos realiza el análisis de opinión de los datos proporcionados para proporcionar resultados sin errores.
 Reconocimiento de entidad nombrada (NER):
Reconocimiento de entidad nombrada (NER): - Análisis de intención y conversación: La detección de intenciones tiene como objetivo entrenar a la IA para que reconozca la intención del hablante. Se utiliza principalmente para crear chatbots impulsados por IA.
Conclusión
La tecnología de voz a texto se encuentra en una gran etapa en este momento. Con más dispositivos digitales que incorporan búsqueda por voz y asistentes de control en sus aplicaciones, la demanda de transcripción de audio aumentará. Si está interesado en agregar esta característica impresionante a su aplicación, comuníquese con los expertos en recopilación de datos de voz de Shaip para conocer todos los detalles.


