
Una solución sólida basada en IA se basa en datos, no solo en cualquier dato, sino en datos de alta calidad y anotados con precisión. Solo los mejores y más refinados datos pueden impulsar su proyecto de IA, y esta pureza de datos tendrá un gran impacto en el resultado del proyecto.
A menudo hemos llamado a los datos el combustible para los proyectos de IA, pero no sirve cualquier dato. Si necesita combustible para cohetes para ayudar a que su proyecto despegue, no puede poner petróleo crudo en el tanque. En cambio, los datos (como el combustible) deben refinarse cuidadosamente para garantizar que solo la información de la más alta calidad impulse su proyecto. Ese proceso de refinamiento se llama anotación de datos, y existen bastantes conceptos erróneos persistentes al respecto.
Definir la calidad de los datos de entrenamiento en la anotación
Sabemos que la calidad de los datos marca una gran diferencia en el resultado del proyecto de IA. Algunos de los mejores y más altos modelos de ML se han basado en conjuntos de datos detallados y etiquetados con precisión.
Pero, ¿cómo definimos exactamente la calidad en una anotación?
Cuando hablamos de anotación de datos calidad, la precisión, la fiabilidad y la coherencia son importantes. Se dice que un conjunto de datos es preciso si coincide con la verdad del terreno y la información del mundo real.
La consistencia de los datos se refiere al nivel de precisión que se mantiene en todo el conjunto de datos. Sin embargo, la calidad de un conjunto de datos se determina con mayor precisión por el tipo de proyecto, sus requisitos únicos y el resultado deseado. Por lo tanto, este debería ser el criterio para determinar el etiquetado de datos y la calidad de las anotaciones.
¿Por qué es importante definir la calidad de los datos?
Es importante definir la calidad de los datos, ya que actúa como un factor integral que determina la calidad del proyecto y el resultado.
- Los datos de mala calidad pueden afectar el producto y las estrategias comerciales.
- Un sistema de aprendizaje automático es tan bueno como la calidad de los datos en los que se entrena.
- Los datos de buena calidad eliminan el retrabajo y los costos asociados con él.
- Ayuda a las empresas a tomar decisiones informadas sobre proyectos y se adhiere al cumplimiento normativo.
¿Cómo medimos la calidad de los datos de entrenamiento durante el etiquetado?

Existen varios métodos para medir la calidad de los datos de entrenamiento, y la mayoría de ellos comienzan con la creación de una guía de anotación de datos concreta. Algunos de los métodos incluyen:
Puntos de referencia establecidos por expertos
Puntos de referencia de calidad o anotación estándar de oro Los métodos son las opciones de aseguramiento de la calidad más sencillas y asequibles que sirven como punto de referencia para medir la calidad de los resultados del proyecto. Mide las anotaciones de datos contra el punto de referencia establecido por los expertos.
Prueba Alfa de Cronbach
La prueba alfa de Cronbach determina la correlación o consistencia entre los elementos del conjunto de datos. La fiabilidad de la etiqueta y mayor precisión se puede medir en base a la investigación.
Medición de consenso
La medición de consenso determina el nivel de acuerdo entre anotadores humanos o de máquinas. Por lo general, se debe llegar a un consenso para cada elemento y se debe arbitrar en caso de desacuerdo.
Revisión del panel
Un panel de expertos generalmente determina la precisión de la etiqueta al revisar las etiquetas de datos. A veces, una parte definida de las etiquetas de datos suele tomarse como muestra para determinar la precisión.
Revisión Datos de entrenamiento Quality
Las empresas que asumen proyectos de inteligencia artificial están totalmente compradas en el poder de la automatización, por lo que muchos continúan pensando que la anotación automática impulsada por la inteligencia artificial será más rápida y precisa que la anotación manual. Por ahora, la realidad es que se necesitan humanos para identificar y clasificar los datos porque la precisión es muy importante. Los errores adicionales creados a través del etiquetado automático requerirán iteraciones adicionales para mejorar la precisión del algoritmo, anulando cualquier ahorro de tiempo.
Otro concepto erróneo, y uno que probablemente contribuya a la adopción de la anotación automática, es que los pequeños errores no tienen mucho efecto en los resultados. Incluso los errores más pequeños pueden producir inexactitudes significativas debido a un fenómeno llamado deriva de la IA, donde las inconsistencias en los datos de entrada llevan a un algoritmo en una dirección que los programadores nunca pretendieron.
La calidad de los datos de capacitación, los aspectos de precisión y consistencia, se revisan constantemente para cumplir con las demandas únicas de los proyectos. Por lo general, se realiza una revisión de los datos de entrenamiento utilizando dos métodos diferentes:
Técnicas autoanotadas
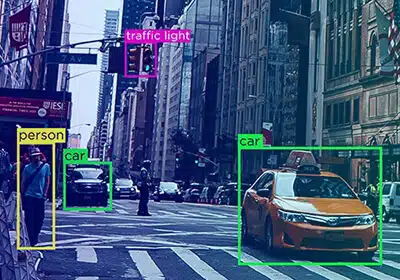 El proceso de revisión automática de anotaciones garantiza que los comentarios vuelvan al sistema y evita las falacias para que los anotadores puedan mejorar sus procesos.
El proceso de revisión automática de anotaciones garantiza que los comentarios vuelvan al sistema y evita las falacias para que los anotadores puedan mejorar sus procesos.
La anotación automática impulsada por inteligencia artificial es precisa y más rápida. La anotación automática reduce el tiempo que los QA manuales dedican a la revisión, lo que les permite dedicar más tiempo a errores complejos y críticos en el conjunto de datos. La anotación automática también puede ayudar a detectar respuestas no válidas, repeticiones y anotaciones incorrectas.
Manualmente a través de expertos en ciencia de datos
Los científicos de datos también revisan la anotación de datos para garantizar la precisión y la confiabilidad en el conjunto de datos.
Los pequeños errores y las imprecisiones en las anotaciones pueden afectar significativamente el resultado del proyecto. Y estos errores pueden no ser detectados por las herramientas de revisión de anotaciones automáticas. Los científicos de datos realizan pruebas de calidad de muestras de diferentes tamaños de lotes para detectar inconsistencias de datos y errores no deseados en el conjunto de datos.
Detrás de cada titular de IA hay un proceso de anotación, y Shaip puede ayudar a que sea indoloro
Evitar las trampas del proyecto de IA
Muchas organizaciones se ven afectadas por la falta de recursos internos de anotación. Los científicos e ingenieros de datos tienen una gran demanda, y contratar suficientes de estos profesionales para asumir un proyecto de IA significa escribir un cheque que está fuera del alcance de la mayoría de las empresas. En lugar de elegir una opción de presupuesto (como la anotación de crowdsourcing) que eventualmente volverá a atormentarlo, considere subcontratar sus necesidades de anotación a un socio externo experimentado. La subcontratación garantiza un alto grado de precisión al tiempo que reduce los cuellos de botella de contratación, capacitación y administración que surgen cuando intenta reunir un equipo interno.
Cuando subcontratas tus necesidades de anotaciones con Shaip específicamente, aprovechas una fuerza poderosa que puede acelerar tu iniciativa de IA sin los atajos que comprometerán los resultados más importantes. Ofrecemos una fuerza laboral completamente administrada, lo que significa que puede obtener una precisión mucho mayor de la que obtendría a través de los esfuerzos de anotación de crowdsourcing. La inversión inicial puede ser mayor, pero dará sus frutos durante el proceso de desarrollo cuando se necesiten menos iteraciones para lograr el resultado deseado.
Nuestros servicios de datos también cubren todo el proceso, incluido el abastecimiento, que es una capacidad que la mayoría de los demás proveedores de etiquetado no pueden ofrecer. Con nuestra experiencia, puede adquirir rápida y fácilmente grandes volúmenes de datos de alta calidad y geográficamente diversos que han sido desidentificados y cumplen con todas las regulaciones relevantes. Cuando almacena estos datos en nuestra plataforma basada en la nube, también obtiene acceso a herramientas y flujos de trabajo probados que aumentan la eficiencia general de su proyecto y lo ayudan a progresar más rápido de lo que creía posible.
Y finalmente, nuestro expertos internos de la industria entender sus necesidades únicas. Ya sea que esté creando un chatbot o trabajando para aplicar la tecnología de reconocimiento facial para mejorar la atención médica, hemos estado allí y podemos ayudarlo a desarrollar pautas que garantizarán que el proceso de anotación logre los objetivos establecidos para su proyecto.
En Shaip, no solo estamos entusiasmados con la nueva era de la IA. Lo estamos ayudando de maneras increíbles, y nuestra experiencia nos ha ayudado a hacer despegar innumerables proyectos exitosos. Para ver qué podemos hacer para su propia implementación, comuníquese con nosotros para solicite una demo .


