
Los datos son la superpotencia que está transformando el panorama digital en el mundo actual. Desde correos electrónicos hasta publicaciones en redes sociales, hay datos en todas partes. Es cierto que las empresas nunca han tenido acceso a tantos datos, pero ¿es suficiente tener acceso a los datos? La rica fuente de información se vuelve inútil u obsoleta cuando no se procesa.
El texto no estructurado puede ser una rica fuente de información, pero no será útil para las empresas a menos que los datos estén organizados, categorizados y analizados. Los datos no estructurados, como texto, audio, videos y redes sociales, ascienden a 80 -90% de todos los datos. Además, según se informa, apenas el 18 % de las organizaciones aprovechan los datos no estructurados de su organización.
Examinar manualmente terabytes de datos almacenados en los servidores es una tarea que requiere mucho tiempo y es francamente imposible. Sin embargo, con los avances en el aprendizaje automático, el procesamiento del lenguaje natural y la automatización, es posible estructurar y analizar datos de texto de forma rápida y eficaz. El primer paso en el análisis de datos es clasificación de texto.
¿Qué es la clasificación de texto?
La clasificación o categorización de texto es el proceso de agrupar texto en categorías o clases predeterminadas. Con este enfoque de aprendizaje automático, cualquier texto: documentos, archivos web, estudios, documentos legales, informes médicos y más – pueden clasificarse, organizarse y estructurarse.
La clasificación de texto es el paso básico en el procesamiento del lenguaje natural que tiene varios usos en la detección de spam. Análisis de opinión, detección de intenciones, etiquetado de datos y más.
Posibles casos de uso de clasificación de texto
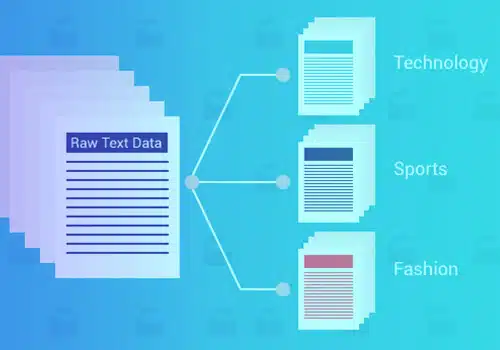 El uso de la clasificación de texto de aprendizaje automático tiene varios beneficios, como la escalabilidad, la velocidad de análisis, la coherencia y la capacidad de tomar decisiones rápidas basadas en conversaciones en tiempo real.
El uso de la clasificación de texto de aprendizaje automático tiene varios beneficios, como la escalabilidad, la velocidad de análisis, la coherencia y la capacidad de tomar decisiones rápidas basadas en conversaciones en tiempo real.
Cuando el modelo ML se entrena en IA que categoriza automáticamente los elementos en categorías preestablecidas, puede convertir rápidamente a los navegadores casuales en clientes.
Proceso de clasificación de texto
El proceso de clasificación de texto comienza con el procesamiento previo, la selección de características, la extracción y la clasificación de datos.

Preprocesamiento
Tokenización: El texto se divide en formas de texto más pequeñas y simples para facilitar la clasificación.
Normalización: Todo el texto de un documento debe estar en el mismo nivel de comprensión. Algunas formas de normalización incluyen,
- Mantener los estándares gramaticales o estructurales en todo el texto, como la eliminación de espacios en blanco o puntuaciones. O manteniendo las minúsculas en todo el texto.
- Eliminar prefijos y sufijos de las palabras y devolverlos a su palabra raíz.
- Eliminar palabras vacías como 'y' 'es' 'el' y más que no agregan valor al texto.
Selección de características
La selección de características es un paso fundamental en la clasificación del texto. El proceso está dirigido a representar textos con la característica más relevante. Las selecciones de funciones ayudan a eliminar datos irrelevantes y mejoran la precisión.
La selección de funciones reduce la variable de entrada en el modelo utilizando solo los datos más relevantes y eliminando el ruido. Según el tipo de solución que busque, sus modelos de IA se pueden diseñar para elegir solo las características relevantes del texto.
Extracción de características
La extracción de características es un paso opcional que algunas empresas realizan para extraer características clave adicionales en los datos. La extracción de características utiliza varias técnicas, como mapeo, filtrado y agrupación. El beneficio principal de usar la extracción de características es que ayuda a eliminar datos redundantes y mejora la velocidad con la que se desarrolla el modelo ML.
Etiquetado de datos en categorías predeterminadas
Etiquetar texto en categorías predefinidas es el paso final en la clasificación de texto. Se puede hacer de tres formas diferentes,
- Etiquetado manual
- Coincidencia basada en reglas
- Algoritmos de aprendizaje: los algoritmos de aprendizaje se pueden clasificar en dos categorías, como etiquetado supervisado y etiquetado no supervisado.
- Aprendizaje supervisado: el modelo ML puede alinear automáticamente las etiquetas con los datos categorizados existentes en el etiquetado supervisado. Cuando los datos categorizados ya están disponibles, los algoritmos de ML pueden mapear la función entre las etiquetas y el texto.
- Aprendizaje no supervisado: ocurre cuando hay escasez de datos etiquetados previamente existentes. Los modelos de ML utilizan algoritmos de agrupamiento y basados en reglas para agrupar textos similares, por ejemplo, en función del historial de compras de productos, reseñas, detalles personales y boletos. Estos grupos amplios se pueden analizar más a fondo para obtener información valiosa específica del cliente que se puede utilizar para diseñar enfoques personalizados para el cliente.
Hay múltiples casos de uso para la clasificación de texto en todas las industrias. Aunque la recopilación, agrupación, clasificación y extracción de información valiosa de los datos de texto siempre se ha utilizado en varios campos, la clasificación de texto está encontrando su potencial en marketing, desarrollo de productos, servicio al cliente, gestión y administración. Está ayudando a las empresas a obtener inteligencia competitiva, conocimiento del mercado y del cliente, y a tomar decisiones comerciales respaldadas por datos.
Desarrollar una herramienta de clasificación de texto eficaz y perspicaz no es fácil. Aún así, con Shaip como su socio de datos, puede desarrollar una herramienta de clasificación de texto basada en IA efectiva, escalable y rentable. Tenemos toneladas de conjuntos de datos anotados con precisión y listos para usar que se pueden personalizar para los requisitos únicos de su modelo. Convertimos tu texto en una ventaja competitiva; ponte en contacto hoy


