
La clave para superar los obstáculos del desarrollo de la IA: datos más fiables
Hoy en día, la persona promedio ahora tiene millones de veces más poder de computación en su bolsillo de lo que la NASA tuvo para lograr el alunizaje en 1969. Ese mismo dispositivo ubicuo que demuestra convenientemente una abundancia de poder de computación también está cumpliendo otro prerrequisito para la edad de oro de la IA: abundancia de datos. Según los conocimientos del Information Overload Research Group, el 90% de los datos del mundo se crearon en los últimos dos años. Ahora que el crecimiento exponencial en el poder de la computación finalmente ha convergido con un crecimiento igualmente meteórico en la generación de datos, las innovaciones de datos de inteligencia artificial están explotando tanto que algunos expertos creen que impulsarán una Cuarta Revolución Industrial.
Los datos de la Asociación Nacional de Capital de Riesgo indican que el sector de la inteligencia artificial registró una inversión récord de $ 6.9 mil millones en el primer trimestre de 2020. No es difícil ver el potencial de las herramientas de inteligencia artificial porque ya se está aprovechando a nuestro alrededor. Algunos de los casos de uso más visibles para los productos de inteligencia artificial son los motores de recomendación detrás de nuestras aplicaciones favoritas, como Spotify y Netflix. Aunque es divertido descubrir un nuevo artista para escuchar o un nuevo programa de televisión para ver, estas implementaciones son de poca importancia. Otros algoritmos califican los puntajes de las pruebas, que determinan en parte dónde se acepta a los estudiantes en la universidad, y otros analizan los currículums de los candidatos, decidiendo qué solicitantes obtienen un trabajo en particular. Algunas herramientas de IA pueden incluso tener implicaciones de vida o muerte, como el modelo de IA que detecta el cáncer de mama (que supera a los médicos).
A pesar del crecimiento constante tanto en los ejemplos del mundo real de desarrollo de IA como en la cantidad de nuevas empresas que compiten por crear la próxima generación de herramientas de transformación, persisten los desafíos para el desarrollo y la implementación efectivos. En particular, la salida de AI es tan precisa como lo permite la entrada, lo que significa que la calidad es primordial.

Navegando las complejas demandas de cumplimiento
Como si encontrar datos de calidad no fuera lo suficientemente difícil, algunas de las industrias que pueden beneficiarse al máximo de las innovaciones de datos de inteligencia artificial también son las más reguladas. La atención médica es quizás el mejor ejemplo, y aunque una encuesta de HIT Infrastructure encontró que el 91% de los expertos de la industria piensan que la tecnología podría mejorar el acceso a la atención, ese optimismo se ve atenuado por el hecho de que el 75% lo ve como una amenaza para la seguridad y privacidad del paciente. - y los pacientes no son los únicos en riesgo.
Las amplias regulaciones promulgadas a través de la Ley de Portabilidad y Responsabilidad de los Seguros de Salud ahora se cruzan con varios obstáculos de cumplimiento de datos locales, como el Reglamento General de Protección de Datos de Europa, la Ley de Privacidad del Consumidor de California en los Estados Unidos y la Ley de Protección de Datos Personales en Singapur. A estas regulaciones locales se unirán muchas más y, a medida que la telesalud emerja como una fuente más importante de datos de atención médica, es probable que las regulaciones obtengan un control aún más estricto sobre los datos de los pacientes en tránsito. Como resultado, la plataforma en la nube segura y compatible de Shaip demostrará ser un medio aún más valioso para acumular y acceder a datos de atención médica para entrenar productos de inteligencia artificial.
La información de identificación personal puede ser una amenaza significativa para el desarrollo de su inteligencia artificial, pero incluso una implementación completamente compatible está en riesgo si no puede ofrecer el tipo de resultados precisos que solo vienen con diversos datos de entrenamiento. Un estudio de 2020 en el Journal of the American Medical Association demostró que los algoritmos de aprendizaje automático en el campo médico se entrenan con mayor frecuencia con datos de pacientes en California, Nueva York y Massachusetts. Dado que estos pacientes representan menos de una quinta parte de la población de EE. UU., Por no hablar del resto del mundo, es difícil imaginar cómo estos modelos podrían producir algo más que resultados sesgados.

 Al reconocer la dificultad de asegurar información conforme a las normas y geográficamente diversa, Shaip ofrece datos de atención médica con licencia de una amplia variedad de regiones seleccionadas específicamente con el objetivo de construir algoritmos precisos. Estos datos vienen en forma de texto, como registros médicos o información de reclamos, imágenes de diagnóstico médico como tomografías computarizadas, audio como notas habladas de médicos o conversaciones entre médicos y pacientes, e incluso videos de resultados de resonancia magnética. También está completamente desidentificado y anonimizado, lo que protege a su organización de las implicaciones éticas y financieras que pueden derivarse de una infracción en cualquiera de la creciente cantidad de regulaciones que rigen los datos de origen nacional e internacional.
Al reconocer la dificultad de asegurar información conforme a las normas y geográficamente diversa, Shaip ofrece datos de atención médica con licencia de una amplia variedad de regiones seleccionadas específicamente con el objetivo de construir algoritmos precisos. Estos datos vienen en forma de texto, como registros médicos o información de reclamos, imágenes de diagnóstico médico como tomografías computarizadas, audio como notas habladas de médicos o conversaciones entre médicos y pacientes, e incluso videos de resultados de resonancia magnética. También está completamente desidentificado y anonimizado, lo que protege a su organización de las implicaciones éticas y financieras que pueden derivarse de una infracción en cualquiera de la creciente cantidad de regulaciones que rigen los datos de origen nacional e internacional.
Superar los obstáculos del desarrollo de la IA
Los esfuerzos de desarrollo de IA incluyen obstáculos significativos sin importar en qué industria se desarrollen, y el proceso de pasar de una idea factible a un producto exitoso está plagado de dificultades. Entre los desafíos de adquirir los datos correctos y la necesidad de anonimizarlos para cumplir con todas las regulaciones relevantes, puede parecer que construir y entrenar un algoritmo es la parte fácil.
Para brindarle a su organización todas las ventajas necesarias en el esfuerzo por diseñar un nuevo y revolucionario desarrollo de inteligencia artificial, querrá considerar asociarse con una empresa como Shaip. Chetan Parikh y Vatsal Ghiya fundaron Shaip para ayudar a las empresas a diseñar los tipos de soluciones que podrían transformar la atención médica en los EE. UU. Después de más de 16 años en el negocio, nuestra empresa ha crecido hasta incluir más de 600 miembros del equipo y hemos trabajado con cientos de clientes para convertir ideas convincentes en soluciones de inteligencia artificial.
Con nuestra gente, procesos y plataforma trabajando para su organización, puede desbloquear inmediatamente los siguientes cuatro beneficios y catapultar su proyecto hacia un final exitoso:
1. La capacidad de liberar a sus científicos de datos
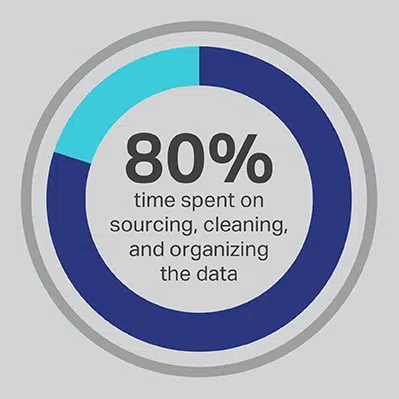
No hay forma de evitar que el proceso de desarrollo de la IA requiera una inversión considerable de tiempo, pero siempre puede optimizar las funciones que su equipo dedica más tiempo a realizar. Contrató a sus científicos de datos porque son expertos en el desarrollo de algoritmos avanzados y modelos de aprendizaje automático, pero la investigación demuestra constantemente que estos trabajadores en realidad dedican el 80% de su tiempo a buscar, limpiar y organizar los datos que impulsarán el proyecto. Más de las tres cuartas partes (76%) de los científicos de datos informan que estos procesos mundanos de recopilación de datos también son sus partes menos favoritas del trabajo, pero la necesidad de datos de calidad deja solo el 20% de su tiempo para el desarrollo real, que es el trabajo más interesante e intelectualmente estimulante para muchos científicos de datos. Al obtener datos a través de un proveedor externo como Shaip, una empresa puede permitir que sus costosos y talentosos ingenieros de datos subcontraten su trabajo como conserjes de datos y, en cambio, dediquen su tiempo a las partes de las soluciones de inteligencia artificial donde pueden producir el mayor valor.
2. La capacidad de lograr mejores resultados
 Muchos líderes de desarrollo de IA deciden utilizar datos de código abierto o de colaboración colectiva para reducir los gastos, pero esta decisión casi siempre termina costando más a largo plazo. Estos tipos de datos están fácilmente disponibles, pero no pueden igualar la calidad de conjuntos de datos cuidadosamente seleccionados. Los datos de colaboración colectiva, en particular, están plagados de errores, omisiones e inexactitudes, y aunque estos problemas a veces pueden resolverse durante el proceso de desarrollo bajo la atenta mirada de sus ingenieros, se requieren iteraciones adicionales que no serían necesarias si comenzara con una -Datos de calidad desde el principio.
Muchos líderes de desarrollo de IA deciden utilizar datos de código abierto o de colaboración colectiva para reducir los gastos, pero esta decisión casi siempre termina costando más a largo plazo. Estos tipos de datos están fácilmente disponibles, pero no pueden igualar la calidad de conjuntos de datos cuidadosamente seleccionados. Los datos de colaboración colectiva, en particular, están plagados de errores, omisiones e inexactitudes, y aunque estos problemas a veces pueden resolverse durante el proceso de desarrollo bajo la atenta mirada de sus ingenieros, se requieren iteraciones adicionales que no serían necesarias si comenzara con una -Datos de calidad desde el principio.
Confiar en datos de código abierto es otro atajo común que viene con su propio conjunto de trampas. La falta de diferenciación es uno de los mayores problemas, porque un algoritmo entrenado con datos de código abierto se replica más fácilmente que uno construido sobre conjuntos de datos con licencia. Al seguir esta ruta, invita a la competencia de otros participantes en el espacio que podrían reducir sus precios y tomar participación de mercado en cualquier momento. Cuando confía en Shaip, está accediendo a los datos de la más alta calidad reunidos por una mano de obra hábil administrada, y podemos otorgarle una licencia exclusiva para un conjunto de datos personalizado que evita que los competidores recreen fácilmente su propiedad intelectual ganada con tanto esfuerzo.
3. Acceso a profesionales experimentados
 Incluso si su lista interna incluye ingenieros calificados y científicos de datos talentosos, sus herramientas de inteligencia artificial pueden beneficiarse de la sabiduría que solo se obtiene a través de la experiencia. Nuestros expertos en la materia han encabezado numerosas implementaciones de IA en sus campos y han aprendido valiosas lecciones a lo largo del camino, y su único objetivo es ayudarlo a lograr el suyo.
Incluso si su lista interna incluye ingenieros calificados y científicos de datos talentosos, sus herramientas de inteligencia artificial pueden beneficiarse de la sabiduría que solo se obtiene a través de la experiencia. Nuestros expertos en la materia han encabezado numerosas implementaciones de IA en sus campos y han aprendido valiosas lecciones a lo largo del camino, y su único objetivo es ayudarlo a lograr el suyo.
Con expertos en el dominio que identifican, organizan, categorizan y etiquetan los datos por usted, sabe que la información utilizada para entrenar su algoritmo puede producir los mejores resultados posibles. También realizamos un control de calidad regular para asegurarnos de que los datos cumplan con los más altos estándares y funcionen según lo previsto, no solo en un laboratorio, sino también en una situación del mundo real.
4. Un cronograma de desarrollo acelerado
El desarrollo de la IA no ocurre de la noche a la mañana, pero puede suceder más rápido cuando se asocia con Shaip. La recopilación y anotación de datos internos crea un cuello de botella operativo significativo que detiene el resto del proceso de desarrollo. Trabajar con Shaip le brinda acceso instantáneo a nuestra amplia biblioteca de datos listos para usar, y nuestros expertos podrán obtener cualquier tipo de información adicional que necesite con nuestro profundo conocimiento de la industria y nuestra red global. Sin la carga del abastecimiento y la anotación, su equipo puede comenzar a trabajar en el desarrollo real de inmediato, y nuestro modelo de capacitación puede ayudar a identificar inexactitudes tempranas para reducir las iteraciones necesarias para cumplir con los objetivos de precisión.
Si no está listo para subcontratar todos los aspectos de su gestión de datos, Shaip también ofrece una plataforma basada en la nube que ayuda a los equipos a producir, modificar y anotar diferentes tipos de datos de manera más eficiente, incluida la compatibilidad con imágenes, video, texto y audio. . ShaipCloud incluye una variedad de herramientas intuitivas de validación y flujo de trabajo, como una solución patentada para rastrear y monitorear cargas de trabajo, una herramienta de transcripción para transcribir grabaciones de audio complejas y difíciles, y un componente de control de calidad para garantizar una calidad sin concesiones. Lo mejor de todo es que es escalable, por lo que puede crecer a medida que aumentan las diversas demandas de su proyecto.
La era de la innovación de la inteligencia artificial apenas está comenzando, y veremos avances e innovaciones increíbles en los próximos años que tienen el potencial de remodelar industrias enteras o incluso alterar la sociedad en su conjunto. En Shaip, queremos utilizar nuestra experiencia para servir como una fuerza transformadora, ayudando a las empresas más revolucionarias del mundo a aprovechar el poder de las soluciones de IA para lograr objetivos ambiciosos.
Tenemos una gran experiencia en aplicaciones de atención médica e inteligencia artificial conversacional, pero también tenemos las habilidades necesarias para entrenar modelos para casi cualquier tipo de aplicación. Para obtener más información sobre cómo Shaip puede ayudarlo a llevar su proyecto desde la idea hasta la implementación, eche un vistazo a los muchos recursos disponibles en nuestro sitio web o comuníquese con nosotros hoy.
