
¿Alguna vez te has preguntado cómo se despiertan los chatbots y los asistentes virtuales cuando dices "Oye, Siri" o "Alexa"? Es debido a la recopilación de expresiones de texto o las palabras desencadenantes integradas en el software que activa el sistema tan pronto como escucha la palabra de activación programada.
Sin embargo, el proceso general de creación de sonidos y datos de pronunciación no es tan simple. Es un proceso que debe llevarse a cabo con la técnica adecuada para obtener los resultados deseados. Por lo tanto, este blog compartirá la ruta para crear buenos enunciados/palabras desencadenantes que funcionen a la perfección con su IA conversacional.
¿Qué son las Enunciaciones?
Los enunciados pueden denominarse frases o palabras desencadenantes que se utilizan para activar un modelo artificialmente inteligente. Cuando su modelo de IA detecta su palabra de activación, automáticamente comienza a registrar la siguiente solicitud del usuario y responde con una acción o respuesta adecuada.
Utterance utiliza el concepto de aprendizaje profundo para enseñarle al software cómo reconocer palabras de activación. Una vez que Wake Word activa el software, el sistema comienza a capturar, decodificar y atender la solicitud. Cuando no está en uso, el sistema sigue escuchando pasivamente las palabras desencadenantes.
Para que su software de IA obtenga resultados precisos, es esencial capturar una gran cantidad de expresiones diferentes para cada intención. Ayuda a un mejor entrenamiento para el modelo de IA.
[También lea: ¿Te gustaría saber cómo te entienden Siri y Alexa??]
Puntos a recordar al crear un depósito de expresiones
Ahora que sabemos que el entrenamiento es importante para los modelos de IA, lo siguiente que debe saber es cómo proporcionar expresiones a los modelos de IA. Por lo general, se crea un repositorio de expresiones para entrenar las IA conversacionales.
Sin embargo, hay varias cosas que recordar al crear repositorios de expresiones. Las siguientes son las cosas a considerar:
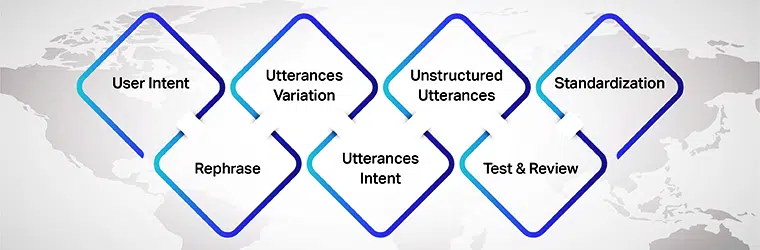
Intención del usuario
Principalmente, mientras prepara expresiones para su modelo de IA, asegúrese de comprender la intención del usuario para la que está desarrollando los conjuntos de datos. Debe averiguar las diferentes expresiones que los usuarios pueden ingresar mientras conversan con el modelo de IA.
Variación de expresiones
Las variaciones son una parte esencial de este proceso, ya que cuantas más variaciones para cada intención, mejores resultados obtendrás. Por lo tanto, asegúrese de crear múltiples variaciones de las declaraciones de los usuarios. Puedes hacerlo por
- Crear oraciones cortas, medianas y largas para las mismas oraciones.
- Cambiar las palabras y la longitud de las oraciones.
- Usando palabras únicas.
- Pluralizar las oraciones.
- Mezclando la gramática.



