

¿Qué son los modelos de lenguaje grande?
Los modelos de lenguaje grande (LLM) son sistemas avanzados de inteligencia artificial (IA) diseñados para procesar, comprender y generar texto similar al humano. Se basan en técnicas de aprendizaje profundo y se entrenan en conjuntos de datos masivos, que generalmente contienen miles de millones de palabras de diversas fuentes, como sitios web, libros y artículos. Esta amplia capacitación permite a los LLM comprender los matices del idioma, la gramática, el contexto e incluso algunos aspectos del conocimiento general.
Algunos LLM populares, como GPT-3 de OpenAI, emplean un tipo de red neuronal llamada transformador, que les permite manejar tareas de lenguaje complejas con notable competencia. Estos modelos pueden realizar una amplia gama de tareas, tales como:
- Respondiendo preguntas
- Resumen de texto
- Traduciendo idiomas
- Generando contenido
- Incluso participar en conversaciones interactivas con los usuarios
A medida que los LLM continúan evolucionando, tienen un gran potencial para mejorar y automatizar varias aplicaciones en todas las industrias, desde el servicio al cliente y la creación de contenido hasta la educación y la investigación. Sin embargo, también plantean preocupaciones éticas y sociales, como el comportamiento sesgado o el uso indebido, que deben abordarse a medida que avanza la tecnología.

Ejemplos populares de modelos de lenguaje grande
Aquí hay algunos ejemplos destacados de LLM que se usan ampliamente en diferentes verticales de la industria:
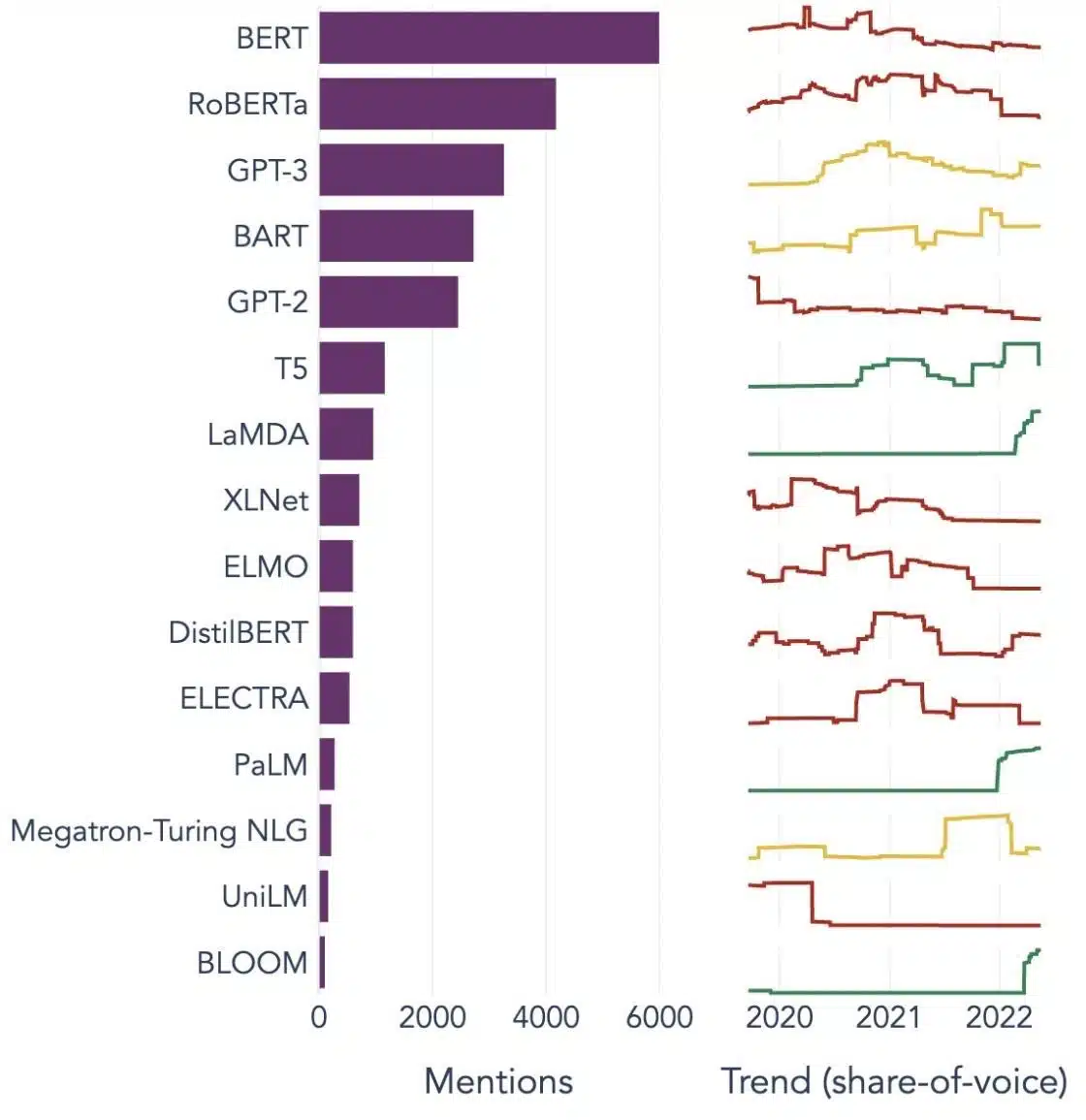
Fuente de imagen: Hacia la ciencia de datos
¿Cómo se entrenan los modelos LLM?
El entrenamiento de modelos de lenguaje grande (LLM) es toda una hazaña que implica varios pasos cruciales. Aquí hay un resumen simplificado paso a paso del proceso:
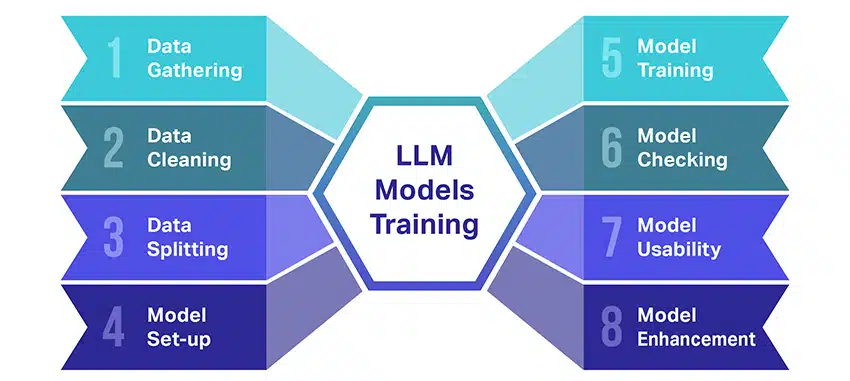
- Recopilación de datos de texto: La capacitación de un LLM comienza con la recopilación de una gran cantidad de datos de texto. Estos datos pueden provenir de libros, sitios web, artículos o plataformas de redes sociales. El objetivo es capturar la rica diversidad del lenguaje humano.
- Limpieza de los datos: Luego, los datos de texto sin procesar se ordenan en un proceso llamado preprocesamiento. Esto incluye tareas como eliminar caracteres no deseados, dividir el texto en partes más pequeñas llamadas tokens y ponerlo todo en un formato con el que el modelo pueda funcionar.
- División de los datos: A continuación, los datos limpios se dividen en dos conjuntos. Un conjunto, los datos de entrenamiento, se usará para entrenar el modelo. El otro conjunto, los datos de validación, se usarán más adelante para probar el rendimiento del modelo.
- Configuración del modelo: Luego se define la estructura del LLM, conocida como arquitectura. Esto implica seleccionar el tipo de red neuronal y decidir sobre varios parámetros, como la cantidad de capas y unidades ocultas dentro de la red.
- Entrenamiento del modelo: Ahora comienza el entrenamiento real. El modelo LLM aprende observando los datos de entrenamiento, haciendo predicciones basadas en lo que ha aprendido hasta el momento y luego ajustando sus parámetros internos para reducir la diferencia entre sus predicciones y los datos reales.
- Comprobación del modelo: El aprendizaje del modelo LLM se comprueba utilizando los datos de validación. Esto ayuda a ver qué tan bien está funcionando el modelo y a ajustar la configuración del modelo para un mejor rendimiento.
- Usando el modelo: Después de la capacitación y evaluación, el modelo LLM está listo para usar. Ahora se puede integrar en aplicaciones o sistemas donde generará texto en función de las nuevas entradas que se le proporcionen.
- Mejorando el modelo: Por último, siempre hay margen de mejora. El modelo LLM se puede perfeccionar aún más con el tiempo, utilizando datos actualizados o ajustando la configuración en función de los comentarios y el uso en el mundo real.
Recuerde, este proceso requiere importantes recursos computacionales, como potentes unidades de procesamiento y gran capacidad de almacenamiento, así como conocimientos especializados en aprendizaje automático. Es por eso que generalmente lo realizan organizaciones dedicadas a la investigación o empresas con acceso a la infraestructura y la experiencia necesarias.
¿El LLM depende del aprendizaje supervisado o no supervisado?
Los modelos de lenguaje grande generalmente se entrenan utilizando un método llamado aprendizaje supervisado. En términos simples, esto significa que aprenden de ejemplos que les muestran las respuestas correctas.
 Imagina que le estás enseñando palabras a un niño mostrándole imágenes. Les muestra una imagen de un gato y dice "gato", y aprenden a asociar esa imagen con la palabra. Así es como funciona el aprendizaje supervisado. El modelo recibe mucho texto (las "imágenes") y los resultados correspondientes (las "palabras"), y aprende a relacionarlos.
Imagina que le estás enseñando palabras a un niño mostrándole imágenes. Les muestra una imagen de un gato y dice "gato", y aprenden a asociar esa imagen con la palabra. Así es como funciona el aprendizaje supervisado. El modelo recibe mucho texto (las "imágenes") y los resultados correspondientes (las "palabras"), y aprende a relacionarlos.
Entonces, si alimentas a un LLM con una oración, intenta predecir la siguiente palabra o frase en función de lo que ha aprendido de los ejemplos. De esta manera, aprende a generar texto que tenga sentido y se ajuste al contexto.
Dicho esto, a veces los LLM también usan un poco de aprendizaje no supervisado. Esto es como dejar que el niño explore una habitación llena de diferentes juguetes y aprenda sobre ellos por su cuenta. El modelo analiza datos no etiquetados, patrones de aprendizaje y estructuras sin que se le indiquen las respuestas "correctas".
El aprendizaje supervisado emplea datos que han sido etiquetados con entradas y salidas, en contraste con el aprendizaje no supervisado, que no usa datos de salida etiquetados.
En pocas palabras, los LLM se capacitan principalmente mediante el aprendizaje supervisado, pero también pueden utilizar el aprendizaje no supervisado para mejorar sus capacidades, como el análisis exploratorio y la reducción de la dimensionalidad.
¿Cuál es el volumen de datos (en GB) necesario para entrenar un modelo de lenguaje grande?
El mundo de posibilidades para el reconocimiento de datos de voz y las aplicaciones de voz es inmenso, y se utilizan en varias industrias para una gran cantidad de aplicaciones.
Entrenar un modelo de lenguaje grande no es un proceso único para todos, especialmente cuando se trata de los datos necesarios. Depende de un montón de cosas:
- El diseño del modelo.
- ¿Qué trabajo necesita hacer?
- El tipo de datos que está utilizando.
- ¿Qué tan bien quieres que funcione?
Dicho esto, la capacitación de LLM generalmente requiere una gran cantidad de datos de texto. Pero, ¿de qué masa estamos hablando? Bueno, piensa mucho más allá de los gigabytes (GB). Por lo general, buscamos terabytes (TB) o incluso petabytes (PB) de datos.
Considere GPT-3, uno de los LLM más grandes que existen. esta entrenado en 570 GB de datos de texto. Los LLM más pequeños pueden necesitar menos, tal vez 10-20 GB o incluso 1 GB de gigabytes, pero aún es mucho.

Pero no se trata solo del tamaño de los datos. La calidad también importa. Los datos deben ser limpios y variados para ayudar al modelo a aprender de manera efectiva. Y no puede olvidarse de otras piezas clave del rompecabezas, como la potencia informática que necesita, los algoritmos que utiliza para el entrenamiento y la configuración de hardware que tiene. Todos estos factores juegan un papel importante en la formación de un LLM.
El auge de los grandes modelos de lenguaje: por qué son importantes
Los LLM ya no son solo un concepto o un experimento. Están desempeñando un papel cada vez más crítico en nuestro panorama digital. Pero ¿por qué sucede esto? ¿Qué hace que estos LLM sean tan importantes? Profundicemos en algunos factores clave.
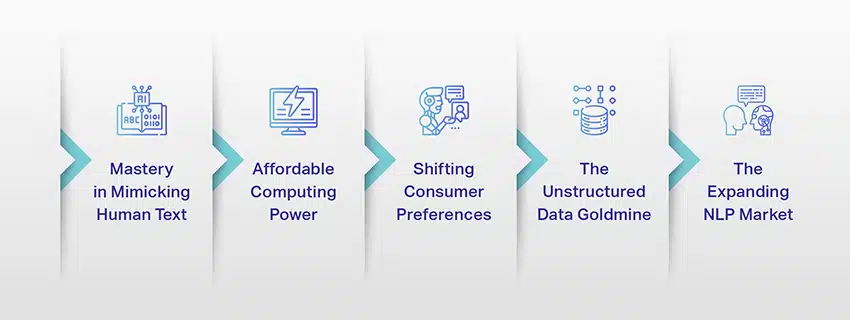
Maestría en imitar texto humano
Los LLM han transformado la forma en que manejamos las tareas basadas en el lenguaje. Construidos con algoritmos robustos de aprendizaje automático, estos modelos están equipados con la capacidad de comprender los matices del lenguaje humano, incluido el contexto, la emoción e incluso el sarcasmo, hasta cierto punto. Esta capacidad de imitar el lenguaje humano no es una mera novedad, tiene implicaciones significativas.
Las capacidades avanzadas de generación de texto de los LLM pueden mejorar todo, desde la creación de contenido hasta las interacciones de servicio al cliente.
Imagine poder hacerle una pregunta compleja a un asistente digital y obtener una respuesta que no solo tenga sentido, sino que también sea coherente, relevante y entregada en un tono conversacional. Eso es lo que están permitiendo los LLM. Están impulsando una interacción hombre-máquina más intuitiva y atractiva, enriqueciendo las experiencias de los usuarios y democratizando el acceso a la información.
Potencia informática asequible
El auge de los LLM no habría sido posible sin desarrollos paralelos en el campo de la informática. Más específicamente, la democratización de los recursos computacionales ha jugado un papel significativo en la evolución y adopción de los LLM.
Las plataformas basadas en la nube ofrecen un acceso sin precedentes a recursos informáticos de alto rendimiento. De esta manera, incluso las organizaciones de pequeña escala y los investigadores independientes pueden entrenar modelos sofisticados de aprendizaje automático.
Además, las mejoras en las unidades de procesamiento (como GPU y TPU), combinadas con el auge de la computación distribuida, han hecho factible entrenar modelos con miles de millones de parámetros. Esta mayor accesibilidad de la potencia informática está permitiendo el crecimiento y el éxito de los LLM, lo que lleva a una mayor innovación y aplicaciones en el campo.
Cambio de preferencias de los consumidores
Los consumidores de hoy no solo quieren respuestas; quieren interacciones atractivas y relacionables. A medida que más personas crecen utilizando la tecnología digital, es evidente que aumenta la necesidad de una tecnología que se sienta más natural y humana. Los LLM ofrecen una oportunidad inigualable para cumplir con estas expectativas. Al generar texto similar al humano, estos modelos pueden crear experiencias digitales atractivas y dinámicas, que pueden aumentar la satisfacción y la lealtad del usuario. Ya sea que se trate de chatbots de IA que brindan servicio al cliente o asistentes de voz que brindan actualizaciones de noticias, los LLM están marcando el comienzo de una era de IA que nos comprende mejor.
La mina de oro de los datos no estructurados
Los datos no estructurados, como correos electrónicos, publicaciones en redes sociales y reseñas de clientes, son un tesoro de información. Se estima que más 80% de los datos empresariales no está estructurado y crece a un ritmo de 55% por año. Estos datos son una mina de oro para las empresas si se aprovechan adecuadamente.
Los LLM entran en juego aquí, con su capacidad para procesar y dar sentido a dichos datos a escala. Pueden manejar tareas como análisis de sentimientos, clasificación de texto, extracción de información y más, proporcionando así información valiosa.
Ya sea identificando tendencias a partir de publicaciones en redes sociales o midiendo el sentimiento de los clientes a partir de reseñas, los LLM están ayudando a las empresas a navegar la gran cantidad de datos no estructurados y a tomar decisiones basadas en datos.
El mercado de la PNL en expansión
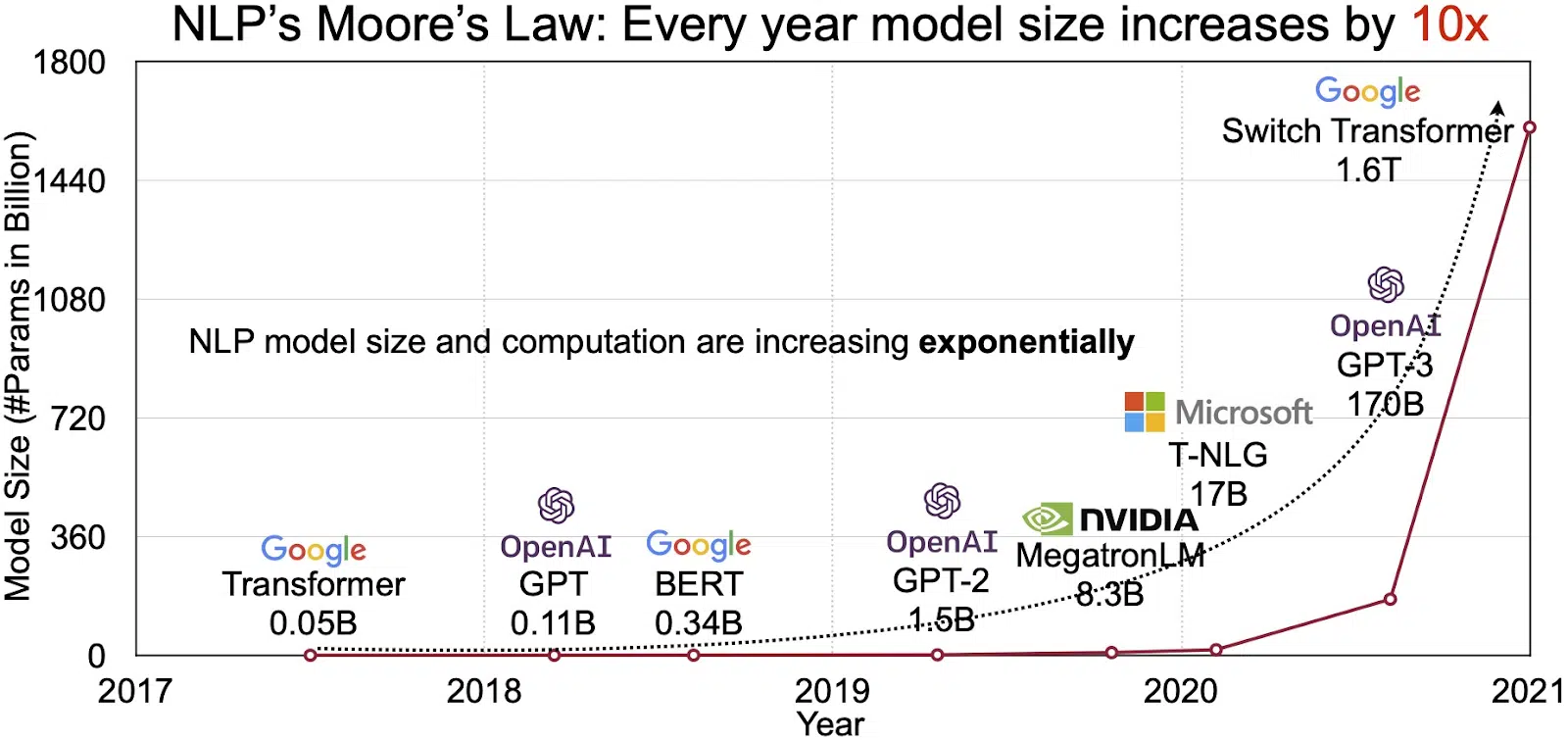
El potencial de los LLM se refleja en el mercado de rápido crecimiento del procesamiento del lenguaje natural (NLP). Los analistas proyectan que el mercado de PNL se expandirá de $ 11 mil millones en 2020 a más de $ 35 mil millones en 2026. Pero no es solo el tamaño del mercado lo que se está expandiendo. Los propios modelos también están creciendo, tanto en tamaño físico como en la cantidad de parámetros que manejan. La evolución de los LLM a lo largo de los años, como se ve en la figura a continuación (fuente de la imagen: enlace), subraya su creciente complejidad y capacidad.
Casos de uso populares de modelos de lenguaje grande
Estos son algunos de los casos de uso principales y más frecuentes de LLM:
- Generación de texto en lenguaje natural: Los modelos de lenguaje grande (LLM) combinan el poder de la inteligencia artificial y la lingüística computacional para producir textos de forma autónoma en lenguaje natural. Pueden satisfacer diversas necesidades de los usuarios, como escribir artículos, crear canciones o entablar conversaciones con los usuarios.
- Traducción a través de Máquinas: Los LLM se pueden emplear de manera efectiva para traducir texto entre cualquier par de idiomas. Estos modelos explotan algoritmos de aprendizaje profundo como redes neuronales recurrentes para comprender la estructura lingüística de los idiomas de origen y de destino, lo que facilita la traducción del texto de origen al idioma deseado.
- Creación de contenido original: Los LLM han abierto vías para que las máquinas generen contenido cohesivo y lógico. Este contenido se puede utilizar para crear publicaciones de blog, artículos y otros tipos de contenido. Los modelos aprovechan su profunda experiencia de aprendizaje profundo para formatear y estructurar el contenido de una manera novedosa y fácil de usar.
- Análisis de sentimientos: Una aplicación intrigante de los modelos de lenguaje grande es el análisis de sentimientos. En esto, el modelo es entrenado para reconocer y categorizar estados emocionales y sentimientos presentes en el texto anotado. El software puede identificar emociones como positividad, negatividad, neutralidad y otros sentimientos intrincados. Esto puede proporcionar información valiosa sobre los comentarios y opiniones de los clientes sobre diversos productos y servicios.
- Comprender, resumir y clasificar el texto: Los LLM establecen una estructura viable para que el software de IA interprete el texto y su contexto. Al instruir al modelo para que comprenda y analice grandes cantidades de datos, los LLM permiten que los modelos de IA comprendan, resuman e incluso clasifiquen texto en diversas formas y patrones.
- Respondiendo preguntas: Los modelos de lenguaje grande equipan los sistemas de respuesta a preguntas (QA) con la capacidad de percibir y responder con precisión a la consulta en lenguaje natural de un usuario. Los ejemplos populares de este caso de uso incluyen ChatGPT y BERT, que examinan el contexto de una consulta y analizan una amplia colección de textos para brindar respuestas relevantes a las preguntas de los usuarios.

Etiquetado de parte del discurso (POS)
Las palabras en las oraciones se etiquetan con su función gramatical, como verbos, sustantivos, adjetivos, etc. Este proceso ayuda al modelo a comprender la gramática y los vínculos entre las palabras.

Reconocimiento de entidad nombrada (NER)
Las entidades nombradas como organizaciones, ubicaciones y personas dentro de una oración están marcadas. Este ejercicio ayuda al modelo a interpretar los significados semánticos de palabras y frases y brinda respuestas más precisas.

Análisis de los sentimientos
A los datos de texto se les asignan etiquetas de sentimiento como positivo, neutral o negativo, lo que ayuda al modelo a captar el trasfondo emocional de las oraciones. Es particularmente útil para responder a consultas que involucran emociones y opiniones.
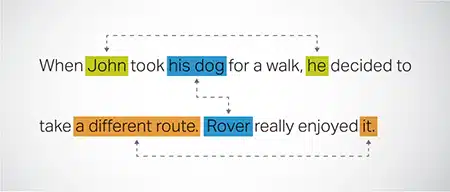
Resolución de correferencia
Identificar y resolver instancias donde se hace referencia a la misma entidad en diferentes partes de un texto. Este paso ayuda al modelo a comprender el contexto de la oración, lo que conduce a respuestas coherentes.
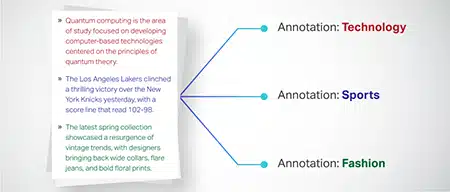
Clasificación de texto
Los datos de texto se clasifican en grupos predefinidos, como reseñas de productos o artículos de noticias. Esto ayuda al modelo a discernir el género o tema del texto, generando respuestas más pertinentes.
Ofrenda de Shaip
Saip ofrece una amplia gama de servicios para ayudar a las organizaciones a administrar, analizar y aprovechar al máximo sus datos.
Web-scraping de datos
Un servicio clave que ofrece Shaip es el raspado de datos. Esto implica la extracción de datos de direcciones URL específicas del dominio. Mediante el uso de herramientas y técnicas automatizadas, Shaip puede extraer rápida y eficientemente grandes volúmenes de datos de varios sitios web, manuales de productos, documentación técnica, foros en línea, reseñas en línea, datos de servicio al cliente, documentos reglamentarios de la industria, etc. Este proceso puede ser invaluable para las empresas cuando recopilar datos relevantes y específicos de una multitud de fuentes.

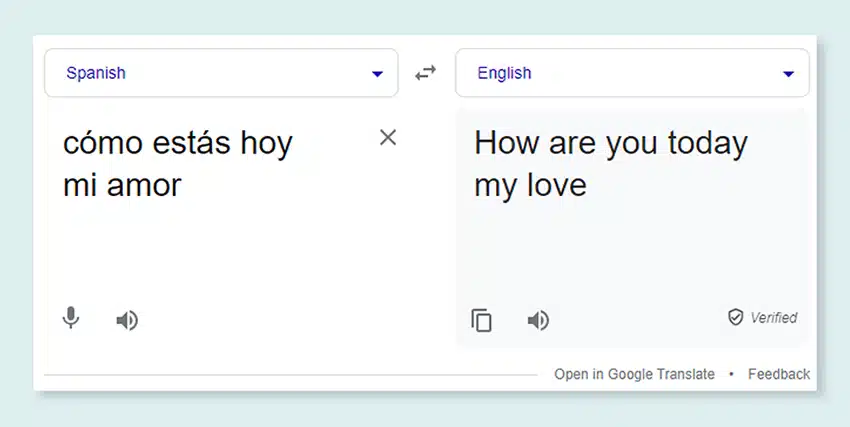
Máquina traductora
Desarrolle modelos utilizando extensos conjuntos de datos multilingües combinados con las transcripciones correspondientes para traducir texto en varios idiomas. Este proceso ayuda a desmantelar los obstáculos lingüísticos y promueve la accesibilidad de la información.
Extracción y creación de taxonomías
Shaip puede ayudar con la extracción y creación de taxonomías. Esto implica clasificar y categorizar datos en un formato estructurado que refleja las relaciones entre diferentes puntos de datos. Esto puede ser particularmente útil para las empresas en la organización de sus datos, haciéndolos más accesibles y fáciles de analizar. Por ejemplo, en un negocio de comercio electrónico, los datos de los productos pueden categorizarse según el tipo de producto, la marca, el precio, etc., lo que facilita a los clientes la navegación por el catálogo de productos.
Recolectar Datos
Nuestros servicios de recopilación de datos proporcionan datos críticos del mundo real o sintéticos necesarios para entrenar algoritmos de IA generativos y mejorar la precisión y eficacia de sus modelos. Los datos se obtienen de manera imparcial, ética y responsable, teniendo en cuenta la privacidad y la seguridad de los datos.

Preguntas y respuestas
La respuesta a preguntas (QA) es un subcampo del procesamiento del lenguaje natural centrado en responder automáticamente preguntas en lenguaje humano. Los sistemas de control de calidad están capacitados en texto y código extensos, lo que les permite manejar varios tipos de preguntas, incluidas las basadas en hechos, definiciones y opiniones. El conocimiento del dominio es crucial para desarrollar modelos de control de calidad adaptados a campos específicos como atención al cliente, atención médica o cadena de suministro. Sin embargo, los enfoques generativos de control de calidad permiten que los modelos generen texto sin conocimiento del dominio, basándose únicamente en el contexto.
Nuestro equipo de especialistas puede estudiar meticulosamente documentos o manuales completos para generar pares Pregunta-Respuesta, lo que facilita la creación de IA Generativa para las empresas. Este enfoque puede abordar de manera efectiva las consultas de los usuarios mediante la extracción de información pertinente de un corpus extenso. Nuestros expertos certificados garantizan la producción de pares de preguntas y respuestas de alta calidad que abarcan diversos temas y dominios.

Resumen de texto
Nuestros especialistas son capaces de destilar conversaciones completas o diálogos extensos, brindando resúmenes breves y perspicaces a partir de extensos datos de texto.

Generación de texto
Entrene modelos utilizando un amplio conjunto de datos de texto en diversos estilos, como artículos de noticias, ficción y poesía. Estos modelos pueden generar varios tipos de contenido, incluidas noticias, entradas de blog o publicaciones en redes sociales, lo que ofrece una solución rentable y que ahorra tiempo para la creación de contenido.
Reconocimiento de voz
Desarrollar modelos capaces de comprender el lenguaje hablado para diversas aplicaciones. Esto incluye asistentes activados por voz, software de dictado y herramientas de traducción en tiempo real. El proceso implica utilizar un conjunto de datos integral compuesto por grabaciones de audio del lenguaje hablado, junto con sus transcripciones correspondientes.

Recomendaciones de productos
Desarrolle modelos utilizando extensos conjuntos de datos de los historiales de compra de los clientes, incluidas las etiquetas que señalan los productos que los clientes se inclinan a comprar. El objetivo es proporcionar sugerencias precisas a los clientes, impulsando así las ventas y mejorando la satisfacción del cliente.
Subtítulos de imágenes
Revolucione su proceso de interpretación de imágenes con nuestro servicio de subtítulos de imágenes impulsado por IA de última generación. Infundimos vitalidad a las imágenes al producir descripciones precisas y contextualmente significativas. Esto allana el camino para posibilidades innovadoras de compromiso e interacción con su contenido visual para su audiencia.

Servicios de formación de texto a voz
Proporcionamos un extenso conjunto de datos compuesto por grabaciones de audio de voz humana, ideal para entrenar modelos de IA. Estos modelos son capaces de generar voces naturales y atractivas para sus aplicaciones, brindando así una experiencia de sonido distintiva e inmersiva para sus usuarios.



