




Potenciar la atención sanitaria con IA generativa: revolucionar el diagnóstico y el tratamiento
En los últimos años, la inteligencia artificial (IA) ha logrado avances significativos en diversas industrias y la atención médica no es una excepción. IA generativa, un subconjunto de la IA centrada
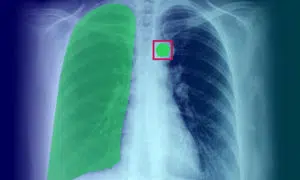
Anotación de imágenes médicas: definición, aplicación, casos de uso y tipos
La anotación de imágenes médicas desempeña un papel fundamental a la hora de proporcionar a los algoritmos de aprendizaje automático y a los modelos de IA los datos de entrenamiento necesarios. Este proceso es esencial para

Ética y sesgo: afrontar los desafíos de la colaboración entre humanos y IA en la evaluación de modelos
En la búsqueda por aprovechar el poder transformador de la inteligencia artificial (IA), la comunidad tecnológica enfrenta un desafío crítico: garantizar la integridad ética y minimizar los prejuicios.

El toque humano: mejorar la creatividad de la IA con evaluación subjetiva
En el mundo de la inteligencia artificial (IA) en rápida evolución, la búsqueda de la creatividad ya no es solo una tarea humana. Las tecnologías de IA actuales se están rompiendo

Maximizar la relevancia de la búsqueda con etiquetado de datos: consejos y mejores prácticas
Los usuarios de hoy están sumergidos en grandes cantidades de información, lo que hace que encontrar la información que necesitan sea complejo. La relevancia de la búsqueda mide la precisión de la información y

Cerrando la brecha: integración de la intuición humana en la evaluación del modelo de IA
Introducción En una era en la que la inteligencia artificial (IA) da forma a cada faceta de nuestras vidas, la integración de la intuición humana en la evaluación del modelo de IA surge como

Los mejores conjuntos de datos sanitarios de código abierto para proyectos de aprendizaje automático
El sistema sanitario mundial produce diariamente grandes cantidades de datos médicos, que tienen el potencial de utilizarse para aplicaciones de aprendizaje automático.

Navegando por la privacidad de los datos en la IA: estrategias para el cumplimiento y la innovación
Introducción En el panorama en rápida evolución de la inteligencia artificial (IA), empresas como OpenAI se enfrentan a importantes desafíos para equilibrar la insaciable necesidad de datos con estrictas normas.
El futuro de los datos con reconocimiento inteligente de caracteres (ICR)
Las notas escritas a mano tienen un encanto especial incluso en nuestro mundo digital. El reconocimiento inteligente de caracteres (ICR) ayuda a cerrar la brecha analógica y digital, convirtiendo texto escrito a mano

El impacto de la PNL en el diagnóstico sanitario
El procesamiento del lenguaje natural (PNL) transforma la forma en que interactuamos con la tecnología. Procesa el lenguaje humano para desbloquear un enorme potencial de información. La tecnología tiene el mismo potencial.

Elegir el conjunto de datos de reconocimiento de voz adecuado para su modelo de IA
Imagínate interactuar con Siri o Alexa. Su capacidad para comprender nuestro discurso es fascinante. Esta capacidad surge de los conjuntos de datos utilizados en su entrenamiento. Estos

Conjuntos de datos sanitarios: una bendición para la IA sanitaria
La inteligencia artificial, un término que alguna vez se encontró principalmente en la ciencia ficción, es ahora una realidad que impulsa el crecimiento de diversas industrias. Consultoría estratégica de próximo paso

Aprendizaje por refuerzo con retroalimentación humana: definición y pasos
El aprendizaje por refuerzo (RL) es un tipo de aprendizaje automático. En este enfoque, los algoritmos aprenden a tomar decisiones mediante prueba y error, al igual que lo hacen los humanos.

Causas de las alucinaciones por IA (y técnicas para reducirlas)
Las alucinaciones de IA se refieren a casos en los que los modelos de IA, en particular los modelos de lenguaje grande (LLM), generan información que parece verdadera pero que es incorrecta o no está relacionada con el

¿Qué es la validación clínica? Su guía de mejores prácticas y procesos
Piense en un escenario en el que se desarrolla una nueva herramienta de diagnóstico. Los médicos están entusiasmados con su potencial. Sin embargo, antes de integrarlo en la atención de rutina,

La importancia de la IA ética/IA justa y los tipos de sesgos que se deben evitar
En el floreciente campo de la inteligencia artificial (IA), centrarse en las consideraciones éticas y la justicia es más que un imperativo moral: es una necesidad fundamental para

Resumen de registros médicos de IA: definición, desafíos y mejores prácticas
El crecimiento de los registros médicos en la industria de la salud se ha convertido a la vez en un desafío y una oportunidad. Imagine un mundo donde cada detalle de un

Abstracción de datos clínicos: definición, proceso y más
Los hospitales y clínicas reciben miles de pacientes cada año. Esto requiere una gran cantidad de médicos y enfermeras dedicados. Trabajan incansablemente para brindar atención.

Datos sintéticos en la atención sanitaria: definición, beneficios y desafíos
Imagine un escenario en el que los investigadores estén desarrollando un nuevo fármaco. Necesitan una gran cantidad de datos de pacientes para realizar las pruebas, pero existen preocupaciones importantes sobre la privacidad y

Determinación de expertos de HIPAA para la desidentificación
La Ley de Responsabilidad y Portabilidad del Seguro Médico (HIPAA) establece el estándar para proteger los datos de los pacientes en la atención médica. Un aspecto crucial de esto es desidentificar a los protegidos.

Investigación pionera en oncología con PNL: el avance de Shaip
Descargar el estudio de caso En la lucha para vencer el cáncer, los datos son tan vitales como la determinación. En Shaip, estamos orgullosos de haber permitido un gran salto
El poder del procesamiento del lenguaje natural (PLN) en radiología: mejora del diagnóstico y la eficiencia
La radiología juega un papel crucial en la atención sanitaria. Utiliza técnicas de imágenes como tomografías computarizadas, rayos X y resonancias magnéticas para diagnosticar y tratar diversas afecciones. Lenguaje natural

El papel del procesamiento del lenguaje natural (PNL) en oncología
El cáncer plantea un importante desafío sanitario a nivel mundial. Ocurre cuando las células crecen y se propagan de forma descontrolada. Es la segunda causa de muerte.

Todo lo que necesita saber sobre el aprendizaje por refuerzo a partir de la retroalimentación humana
En 2023 se produjo un aumento masivo en la adopción de herramientas de inteligencia artificial como ChatGPT. Este aumento inició un animado debate y la gente está discutiendo los beneficios de la IA.

El poder de la IA en la industria automotriz
Cuando se trata de integrar la IA en los automóviles, el mundo se encuentra en una encrucijada notable. Imagínese conducir por una carretera muy transitada con IA, gestionando su

Beneficios del texto a voz en todas las industrias
La tecnología de texto a voz (TTS) es una solución innovadora que convierte texto escrito en palabras habladas. Se ha convertido en un punto de inflexión en varias industrias y ha revolucionado

La anotación de datos de la A a la Z
Una guía para principiantes sobre la anotación de datos: consejos y mejores prácticas La guía definitiva para compradores 2024 Tabla de índice Introducción ¿Qué es el aprendizaje automático? Qué es

Guía de desidentificación de datos: todo lo que un principiante necesita saber (en 2024)
En la era de la transformación digital, las organizaciones sanitarias están trasladando rápidamente sus operaciones a plataformas digitales. Si bien esto aporta eficiencia y procesos optimizados, también

IA generativa en la atención sanitaria: aplicaciones, ventajas, desafíos y tendencias futuras
La atención sanitaria siempre ha sido un campo donde la innovación se valora y es crucial para salvar vidas. A pesar de los avances tecnológicos, la industria de la salud todavía enfrenta desafíos persistentes.

Diferencia entre IA responsable e IA ética
Se espera que el mercado mundial de IA, de rápido crecimiento, alcance los 1847 mil millones de dólares en 2030. Con la IA ocupando un lugar central en nuestras vidas, saber qué tipo de



















Potenciar la atención sanitaria con IA generativa: revolucionar el diagnóstico y el tratamiento
En los últimos años, la inteligencia artificial (IA) ha logrado avances significativos en diversas industrias y la atención médica no es una excepción. IA generativa, un subconjunto de la IA centrada
Anotación de imágenes médicas: definición, aplicación, casos de uso y tipos
La anotación de imágenes médicas desempeña un papel fundamental a la hora de proporcionar a los algoritmos de aprendizaje automático y a los modelos de IA los datos de entrenamiento necesarios. Este proceso es esencial para
Ética y sesgo: afrontar los desafíos de la colaboración entre humanos y IA en la evaluación de modelos
En la búsqueda por aprovechar el poder transformador de la inteligencia artificial (IA), la comunidad tecnológica enfrenta un desafío crítico: garantizar la integridad ética y minimizar los prejuicios.
El toque humano: mejorar la creatividad de la IA con evaluación subjetiva
En el mundo de la inteligencia artificial (IA) en rápida evolución, la búsqueda de la creatividad ya no es solo una tarea humana. Las tecnologías de IA actuales se están rompiendo
Maximizar la relevancia de la búsqueda con etiquetado de datos: consejos y mejores prácticas
Los usuarios de hoy están sumergidos en grandes cantidades de información, lo que hace que encontrar la información que necesitan sea complejo. La relevancia de la búsqueda mide la precisión de la información y
Cerrando la brecha: integración de la intuición humana en la evaluación del modelo de IA
Introducción En una era en la que la inteligencia artificial (IA) da forma a cada faceta de nuestras vidas, la integración de la intuición humana en la evaluación del modelo de IA surge como
Los mejores conjuntos de datos sanitarios de código abierto para proyectos de aprendizaje automático
El sistema sanitario mundial produce diariamente grandes cantidades de datos médicos, que tienen el potencial de utilizarse para aplicaciones de aprendizaje automático.
Navegando por la privacidad de los datos en la IA: estrategias para el cumplimiento y la innovación
Introducción En el panorama en rápida evolución de la inteligencia artificial (IA), empresas como OpenAI se enfrentan a importantes desafíos para equilibrar la insaciable necesidad de datos con estrictas normas.
El futuro de los datos con reconocimiento inteligente de caracteres (ICR)
Las notas escritas a mano tienen un encanto especial incluso en nuestro mundo digital. El reconocimiento inteligente de caracteres (ICR) ayuda a cerrar la brecha analógica y digital, convirtiendo texto escrito a mano
El impacto de la PNL en el diagnóstico sanitario
El procesamiento del lenguaje natural (PNL) transforma la forma en que interactuamos con la tecnología. Procesa el lenguaje humano para desbloquear un enorme potencial de información. La tecnología tiene el mismo potencial.
Elegir el conjunto de datos de reconocimiento de voz adecuado para su modelo de IA
Imagínate interactuar con Siri o Alexa. Su capacidad para comprender nuestro discurso es fascinante. Esta capacidad surge de los conjuntos de datos utilizados en su entrenamiento. Estos
Conjuntos de datos sanitarios: una bendición para la IA sanitaria
La inteligencia artificial, un término que alguna vez se encontró principalmente en la ciencia ficción, es ahora una realidad que impulsa el crecimiento de diversas industrias. Consultoría estratégica de próximo paso
Aprendizaje por refuerzo con retroalimentación humana: definición y pasos
El aprendizaje por refuerzo (RL) es un tipo de aprendizaje automático. En este enfoque, los algoritmos aprenden a tomar decisiones mediante prueba y error, al igual que lo hacen los humanos.
Causas de las alucinaciones por IA (y técnicas para reducirlas)
Las alucinaciones de IA se refieren a casos en los que los modelos de IA, en particular los modelos de lenguaje grande (LLM), generan información que parece verdadera pero que es incorrecta o no está relacionada con el
¿Qué es la validación clínica? Su guía de mejores prácticas y procesos
Piense en un escenario en el que se desarrolla una nueva herramienta de diagnóstico. Los médicos están entusiasmados con su potencial. Sin embargo, antes de integrarlo en la atención de rutina,
La importancia de la IA ética/IA justa y los tipos de sesgos que se deben evitar
En el floreciente campo de la inteligencia artificial (IA), centrarse en las consideraciones éticas y la justicia es más que un imperativo moral: es una necesidad fundamental para
Resumen de registros médicos de IA: definición, desafíos y mejores prácticas
El crecimiento de los registros médicos en la industria de la salud se ha convertido a la vez en un desafío y una oportunidad. Imagine un mundo donde cada detalle de un
Abstracción de datos clínicos: definición, proceso y más
Los hospitales y clínicas reciben miles de pacientes cada año. Esto requiere una gran cantidad de médicos y enfermeras dedicados. Trabajan incansablemente para brindar atención.
Datos sintéticos en la atención sanitaria: definición, beneficios y desafíos
Imagine un escenario en el que los investigadores estén desarrollando un nuevo fármaco. Necesitan una gran cantidad de datos de pacientes para realizar las pruebas, pero existen preocupaciones importantes sobre la privacidad y
Determinación de expertos de HIPAA para la desidentificación
La Ley de Responsabilidad y Portabilidad del Seguro Médico (HIPAA) establece el estándar para proteger los datos de los pacientes en la atención médica. Un aspecto crucial de esto es desidentificar a los protegidos.
Investigación pionera en oncología con PNL: el avance de Shaip
Descargar el estudio de caso En la lucha para vencer el cáncer, los datos son tan vitales como la determinación. En Shaip, estamos orgullosos de haber permitido un gran salto
El poder del procesamiento del lenguaje natural (PLN) en radiología: mejora del diagnóstico y la eficiencia
La radiología juega un papel crucial en la atención sanitaria. Utiliza técnicas de imágenes como tomografías computarizadas, rayos X y resonancias magnéticas para diagnosticar y tratar diversas afecciones. Lenguaje natural
El papel del procesamiento del lenguaje natural (PNL) en oncología
El cáncer plantea un importante desafío sanitario a nivel mundial. Ocurre cuando las células crecen y se propagan de forma descontrolada. Es la segunda causa de muerte.
Todo lo que necesita saber sobre el aprendizaje por refuerzo a partir de la retroalimentación humana
En 2023 se produjo un aumento masivo en la adopción de herramientas de inteligencia artificial como ChatGPT. Este aumento inició un animado debate y la gente está discutiendo los beneficios de la IA.
El poder de la IA en la industria automotriz
Cuando se trata de integrar la IA en los automóviles, el mundo se encuentra en una encrucijada notable. Imagínese conducir por una carretera muy transitada con IA, gestionando su
Beneficios del texto a voz en todas las industrias
La tecnología de texto a voz (TTS) es una solución innovadora que convierte texto escrito en palabras habladas. Se ha convertido en un punto de inflexión en varias industrias y ha revolucionado
La anotación de datos de la A a la Z
Una guía para principiantes sobre la anotación de datos: consejos y mejores prácticas La guía definitiva para compradores 2024 Tabla de índice Introducción ¿Qué es el aprendizaje automático? Qué es
Guía de desidentificación de datos: todo lo que un principiante necesita saber (en 2024)
En la era de la transformación digital, las organizaciones sanitarias están trasladando rápidamente sus operaciones a plataformas digitales. Si bien esto aporta eficiencia y procesos optimizados, también
IA generativa en la atención sanitaria: aplicaciones, ventajas, desafíos y tendencias futuras
La atención sanitaria siempre ha sido un campo donde la innovación se valora y es crucial para salvar vidas. A pesar de los avances tecnológicos, la industria de la salud todavía enfrenta desafíos persistentes.
Diferencia entre IA responsable e IA ética
Se espera que el mercado mundial de IA, de rápido crecimiento, alcance los 1847 mil millones de dólares en 2030. Con la IA ocupando un lugar central en nuestras vidas, saber qué tipo de

¿Qué es la PNL? Cómo funciona, beneficios, desafíos, ejemplos
Descargar Infografía ¿Qué es la PNL? El procesamiento del lenguaje natural (PNL) es un subcampo de la inteligencia artificial (IA). Permite a los robots analizar y comprender el lenguaje humano,

OCR: definición, beneficios, desafíos y casos de uso [infografía]
OCR es una tecnología que permite a las máquinas leer texto e imágenes impresas. A menudo se usa en aplicaciones comerciales, como la digitalización de documentos para su almacenamiento o procesamiento, y en aplicaciones de consumo, como el escaneo de un recibo para el reembolso de gastos.

El estado de la IA conversacional 2022
El estado de la IA conversacional 2022 ¿Qué es la IA conversacional? Una forma programática e inteligente de ofrecer una experiencia conversacional a conversaciones simuladas con personas reales, a través de la comunicación digital y

¿Qué es la recopilación de datos? Todo lo que un principiante necesita saber
Los modelos inteligentes de #AI/ #ML están en todas partes, ya sea, modelos de atención médica predictivos, diagnóstico proactivo,

¿Qué es el etiquetado de datos? Todo lo que un principiante necesita saber
Descargar infografías Los modelos de inteligencia artificial inteligente deben capacitarse ampliamente para poder identificar patrones, objetos y, finalmente, tomar decisiones confiables. Sin embargo, el capacitado