
Introducción
Esta guía será extremadamente útil para aquellos compradores y tomadores de decisiones que están comenzando a centrar sus pensamientos en los aspectos prácticos del abastecimiento de datos y la implementación de datos, tanto para redes neuronales como para otros tipos de operaciones de inteligencia artificial y aprendizaje automático.

Este artículo está completamente dedicado a arrojar luz sobre qué es el proceso, por qué es inevitable, crucial
factores que las empresas deben considerar cuando se acercan a las herramientas de anotación de datos y más. Por lo tanto, si es dueño de un negocio, prepárese para iluminarse, ya que esta guía lo guiará a través de todo lo que necesita saber sobre la anotación de datos.
Empecemos.
Para aquellos de ustedes que leen el artículo, aquí hay algunos puntos rápidos que encontrarán en la guía:
- Comprender qué es la anotación de datos
- Conozca los diferentes tipos de procesos de anotación de datos.
- Conozca las ventajas de implementar el proceso de anotación de datos
- Obtenga claridad sobre si debe optar por el etiquetado de datos interno o subcontratarlos
- Información sobre cómo elegir la anotación de datos adecuada también
¿Qué es el Aprendizaje Automático?
 Hemos hablado sobre cómo la anotación de datos o etiquetado de datos admite el aprendizaje automático y consiste en etiquetar o identificar componentes. Pero en cuanto al aprendizaje profundo y el aprendizaje automático en sí: la premisa básica del aprendizaje automático es que los sistemas y programas informáticos pueden mejorar sus resultados de formas que se asemejan a los procesos cognitivos humanos, sin ayuda o intervención humana directa, para darnos información. En otras palabras, se convierten en máquinas de autoaprendizaje que, al igual que un ser humano, mejoran en su trabajo con más práctica. Esta "práctica" se obtiene al analizar e interpretar más (y mejores) datos de entrenamiento.
Hemos hablado sobre cómo la anotación de datos o etiquetado de datos admite el aprendizaje automático y consiste en etiquetar o identificar componentes. Pero en cuanto al aprendizaje profundo y el aprendizaje automático en sí: la premisa básica del aprendizaje automático es que los sistemas y programas informáticos pueden mejorar sus resultados de formas que se asemejan a los procesos cognitivos humanos, sin ayuda o intervención humana directa, para darnos información. En otras palabras, se convierten en máquinas de autoaprendizaje que, al igual que un ser humano, mejoran en su trabajo con más práctica. Esta "práctica" se obtiene al analizar e interpretar más (y mejores) datos de entrenamiento.
¿Qué es la anotación de datos?
La anotación de datos es el proceso de atribución, etiquetado o etiquetado de datos para ayudar a los algoritmos de aprendizaje automático a comprender y clasificar la información que procesan. Este proceso es esencial para entrenar modelos de IA, lo que les permite comprender con precisión varios tipos de datos, como imágenes, archivos de audio, secuencias de video o texto.
Imagine un automóvil autónomo que se basa en datos de visión por computadora, procesamiento de lenguaje natural (NLP) y sensores para tomar decisiones de conducción precisas. Para ayudar al modelo de IA del automóvil a diferenciar entre obstáculos como otros vehículos, peatones, animales o barricadas, los datos que recibe deben etiquetarse o anotarse.
En el aprendizaje supervisado, la anotación de datos es especialmente crucial, ya que cuantos más datos etiquetados se alimentan al modelo, más rápido aprende a funcionar de forma autónoma. Los datos anotados permiten que los modelos de IA se implementen en varias aplicaciones, como chatbots, reconocimiento de voz y automatización, lo que genera un rendimiento óptimo y resultados confiables.
¿Qué es una herramienta de etiquetado / anotación de datos?
 En términos simples, es una plataforma o un portal que permite a los especialistas y expertos anotar, etiquetar o etiquetar conjuntos de datos de todo tipo. Es un puente o un medio entre los datos sin procesar y los resultados que, en última instancia, producirían sus módulos de aprendizaje automático.
En términos simples, es una plataforma o un portal que permite a los especialistas y expertos anotar, etiquetar o etiquetar conjuntos de datos de todo tipo. Es un puente o un medio entre los datos sin procesar y los resultados que, en última instancia, producirían sus módulos de aprendizaje automático.
Una herramienta de etiquetado de datos es una solución local o basada en la nube que anota datos de entrenamiento de alta calidad para modelos de aprendizaje automático. Si bien muchas empresas confían en un proveedor externo para realizar anotaciones complejas, algunas organizaciones todavía tienen sus propias herramientas que se crean a medida o se basan en herramientas gratuitas o de código abierto disponibles en el mercado. Estas herramientas suelen estar diseñadas para manejar tipos de datos específicos, es decir, imagen, video, texto, audio, etc. Las herramientas ofrecen características u opciones como cuadros delimitadores o polígonos para que los anotadores de datos etiqueten imágenes. Pueden simplemente seleccionar la opción y realizar sus tareas específicas.
Anotación de imagen

A partir de los conjuntos de datos en los que han sido entrenados, pueden diferenciar de manera instantánea y precisa sus ojos de su nariz y su ceja de sus pestañas. Es por eso que los filtros que aplica se ajustan perfectamente independientemente de la forma de su rostro, qué tan cerca esté de su cámara y más.
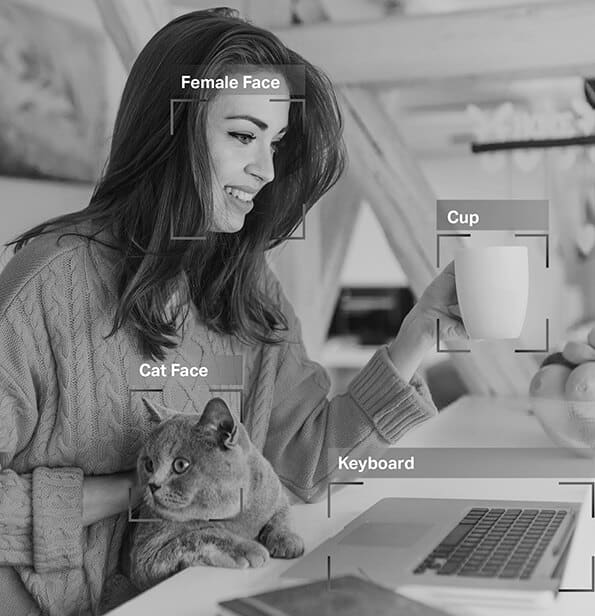
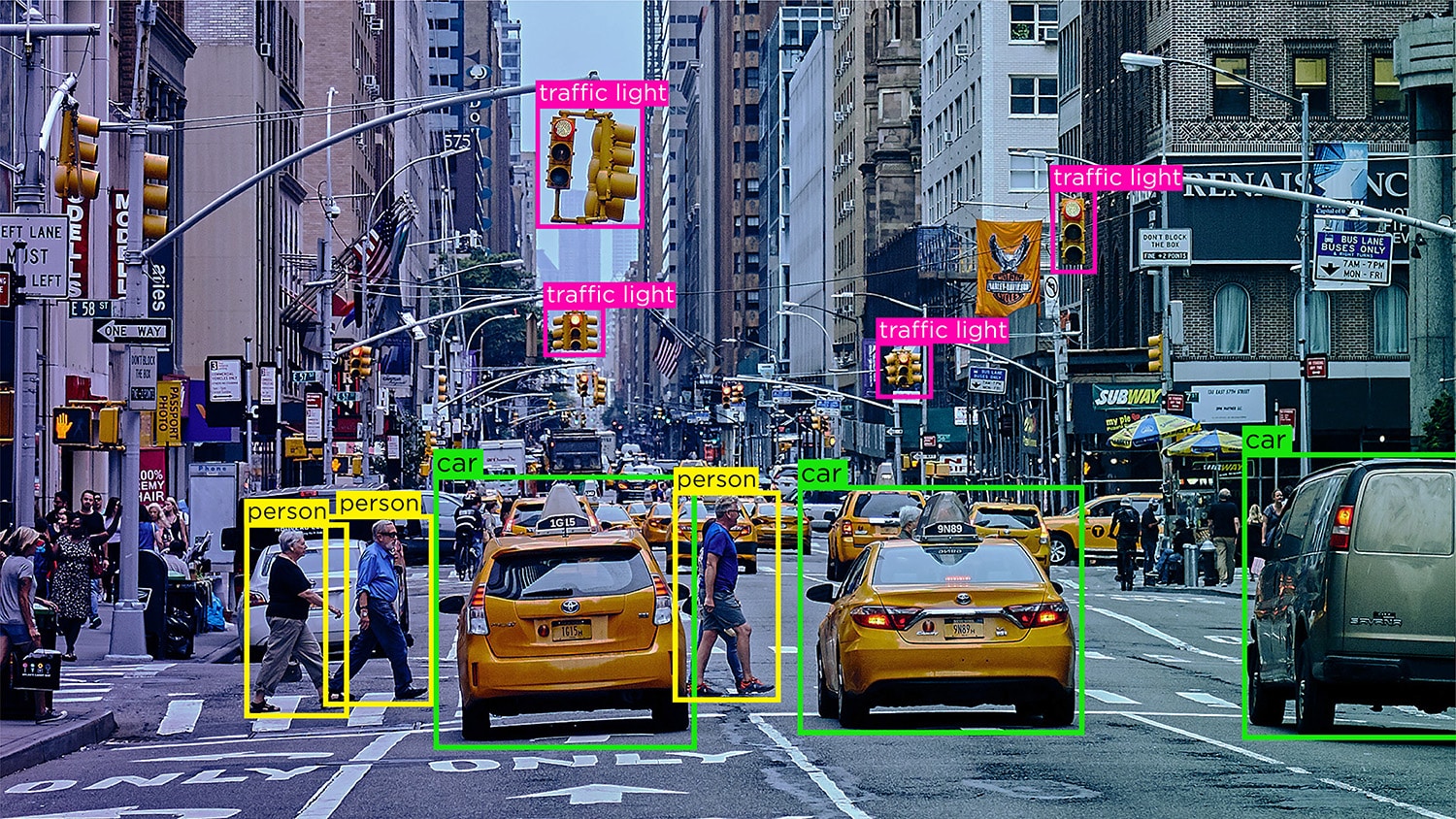
Entonces, como ahora sabes, anotación de imagen es vital en módulos que involucran reconocimiento facial, visión por computadora, visión robótica y más. Cuando los expertos en inteligencia artificial entrenan tales modelos, agregan leyendas, identificadores y palabras clave como atributos a sus imágenes. Los algoritmos luego identifican y comprenden estos parámetros y aprenden de forma autónoma.
Clasificación de imágenes – La clasificación de imágenes implica la asignación de categorías o etiquetas predefinidas a las imágenes en función de su contenido. Este tipo de anotación se usa para entrenar modelos de IA para reconocer y categorizar imágenes automáticamente.
Reconocimiento/Detección de Objetos – El reconocimiento de objetos, o detección de objetos, es el proceso de identificar y etiquetar objetos específicos dentro de una imagen. Este tipo de anotación se usa para entrenar modelos de IA para ubicar y reconocer objetos en imágenes o videos del mundo real.
Segmentación – La segmentación de imágenes consiste en dividir una imagen en varios segmentos o regiones, cada uno de los cuales corresponde a un objeto o área de interés específicos. Este tipo de anotación se utiliza para entrenar modelos de IA para analizar imágenes a nivel de píxel, lo que permite un reconocimiento de objetos y una comprensión de la escena más precisos.
Anotación de audio
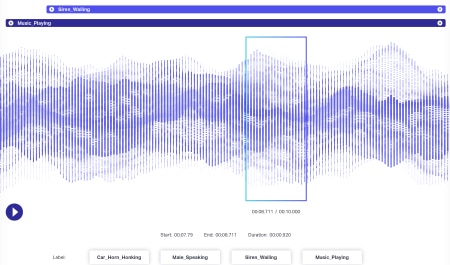
Los datos de audio tienen aún más dinámica adjunta que los datos de imagen. Varios factores están asociados con un archivo de audio, incluidos, entre otros, el idioma, los datos demográficos del hablante, los dialectos, el estado de ánimo, la intención, la emoción y el comportamiento. Para que los algoritmos sean eficientes en el procesamiento, todos estos parámetros deben identificarse y etiquetarse mediante técnicas como la marca de tiempo, el etiquetado de audio y más. Además de las meras señales verbales, las instancias no verbales como el silencio, las respiraciones e incluso el ruido de fondo se pueden anotar para que los sistemas las comprendan de manera integral.
Anotación de video

Mientras una imagen está quieta, un video es una compilación de imágenes que crean un efecto de objetos en movimiento. Ahora, cada imagen de esta compilación se llama marco. En lo que respecta a la anotación de video, el proceso implica la adición de puntos clave, polígonos o cuadros delimitadores para anotar diferentes objetos en el campo en cada cuadro.
Cuando estos marcos se unen, los modelos de IA en acción pueden aprender el movimiento, el comportamiento, los patrones y más. es solo a traves anotación de video que conceptos como la localización, el desenfoque de movimiento y el seguimiento de objetos podrían implementarse en los sistemas.
Anotación de texto

Hoy en día, la mayoría de las empresas dependen de datos basados en texto para obtener información y conocimientos únicos. Ahora, el texto puede ser cualquier cosa, desde los comentarios de los clientes sobre una aplicación hasta una mención en las redes sociales. Y a diferencia de las imágenes y los videos que en su mayoría transmiten intenciones que son directas, el texto viene con mucha semántica.
Como seres humanos, estamos sintonizados para comprender el contexto de una frase, el significado de cada palabra, oración o frase, relacionarlos con una determinada situación o conversación y luego darnos cuenta del significado holístico detrás de una declaración. Las máquinas, por otro lado, no pueden hacer esto a niveles precisos. Conceptos como el sarcasmo, el humor y otros elementos abstractos les son desconocidos y es por eso que el etiquetado de datos de texto se vuelve más difícil. Es por eso que la anotación de texto tiene algunas etapas más refinadas, como las siguientes:
Anotación semántica - los objetos, productos y servicios adquieren mayor relevancia mediante el etiquetado de frases clave y los parámetros de identificación adecuados. Los chatbots también están hechos para imitar conversaciones humanas de esta manera.
Anotación de intención - la intención de un usuario y el idioma utilizado por él están etiquetados para que las máquinas los entiendan. Con esto, los modelos pueden diferenciar una solicitud de un comando, una recomendación de una reserva, etc.
Anotación de opinión – La anotación de opinión implica etiquetar datos textuales con la opinión que transmite, como positivo, negativo o neutral. Este tipo de anotación se usa comúnmente en el análisis de sentimientos, donde los modelos de IA están capacitados para comprender y evaluar las emociones expresadas en el texto.

Anotación de entidad - donde se etiquetan oraciones no estructuradas para hacerlas más significativas y llevarlas a un formato que las máquinas puedan entender. Para que esto suceda, hay dos aspectos involucrados: reconocimiento de entidad nombrada y enlace de entidad. El reconocimiento de entidades nombradas es cuando los nombres de lugares, personas, eventos, organizaciones y más son etiquetados e identificados y la vinculación de entidades es cuando estas etiquetas están vinculadas a oraciones, frases, hechos u opiniones que las siguen. En conjunto, estos dos procesos establecen la relación entre los textos asociados y el enunciado que los rodea.
Categorización de texto – Las oraciones o párrafos se pueden etiquetar y clasificar según temas generales, tendencias, temas, opiniones, categorías (deportes, entretenimiento y similares) y otros parámetros.
Pasos clave en el proceso de etiquetado y anotación de datos
El proceso de anotación de datos implica una serie de pasos bien definidos para garantizar un etiquetado de datos preciso y de alta calidad para aplicaciones de aprendizaje automático. Estos pasos cubren todos los aspectos del proceso, desde la recopilación de datos hasta la exportación de los datos anotados para su uso posterior.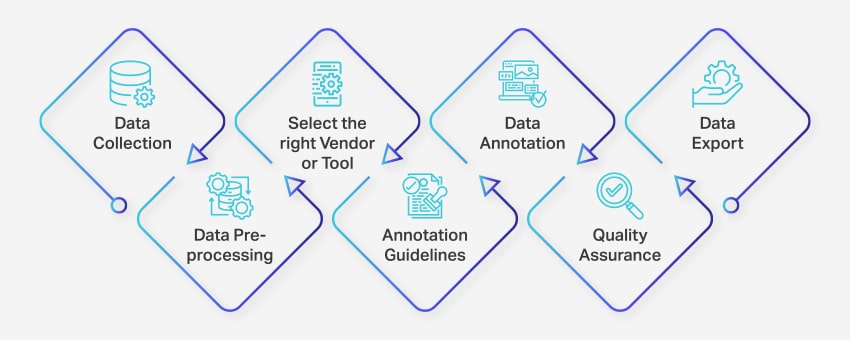
Así es como se lleva a cabo la anotación de datos:
- Recopilación de datos: El primer paso en el proceso de anotación de datos es recopilar todos los datos relevantes, como imágenes, videos, grabaciones de audio o datos de texto, en una ubicación centralizada.
- Preprocesamiento de datos: Estandarice y mejore los datos recopilados corrigiendo imágenes, formateando texto o transcribiendo contenido de video. El preprocesamiento garantiza que los datos estén listos para la anotación.
- Seleccione el proveedor o la herramienta adecuados: Elija una herramienta de anotación de datos o un proveedor adecuado en función de los requisitos de su proyecto. Las opciones incluyen plataformas como Nanonets para anotación de datos, V7 para anotación de imágenes, Appen para anotación de video y Nanonets para anotación de documentos.
- Directrices de anotación: Establezca pautas claras para los anotadores o las herramientas de anotación para garantizar la coherencia y la precisión durante todo el proceso.
- Anotación: Etiquete y etiquete los datos utilizando anotadores humanos o software de anotación de datos, siguiendo las pautas establecidas.
- Garantía de calidad (QA): Revise los datos anotados para garantizar la precisión y la coherencia. Emplee múltiples anotaciones ciegas, si es necesario, para verificar la calidad de los resultados.
- Exportación de datos: Después de completar la anotación de datos, exporte los datos en el formato requerido. Las plataformas como Nanonets permiten exportar datos sin problemas a varias aplicaciones de software empresarial.
Todo el proceso de anotación de datos puede durar desde unos pocos días hasta varias semanas, según el tamaño, la complejidad y los recursos disponibles del proyecto.
Funciones para las herramientas de anotación y etiquetado de datos
Las herramientas de anotación de datos son factores decisivos que podrían hacer o deshacer su proyecto de IA. Cuando se trata de salidas y resultados precisos, la calidad de los conjuntos de datos por sí sola no importa. De hecho, las herramientas de anotación de datos que utiliza para entrenar sus módulos de IA influyen enormemente en sus resultados.
Por eso es fundamental seleccionar y utilizar la herramienta de etiquetado de datos más funcional y adecuada que satisfaga las necesidades de su negocio o proyecto. Pero, ¿qué es una herramienta de anotación de datos en primer lugar? ¿Para qué sirve? ¿Hay tipos? Bueno, averigüémoslo.
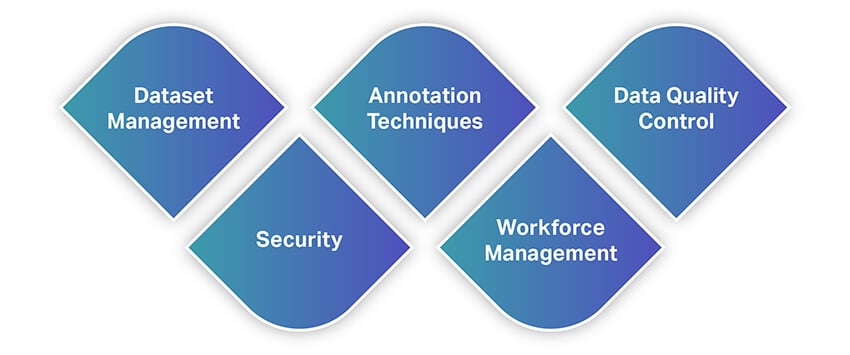
Al igual que otras herramientas, las herramientas de anotación de datos ofrecen una amplia gama de funciones y capacidades. Para darle una idea rápida de las características, aquí hay una lista de algunas de las características más fundamentales que debe buscar al seleccionar una herramienta de anotación de datos.
Gestión de conjunto de datos
La herramienta de anotación de datos que desea utilizar debe admitir los conjuntos de datos que tiene a mano y permitirle importarlos al software para etiquetarlos. Por lo tanto, administrar sus conjuntos de datos es la principal función que ofrecen las herramientas. Las soluciones contemporáneas ofrecen características que le permiten importar grandes volúmenes de datos sin problemas, permitiéndole simultáneamente organizar sus conjuntos de datos a través de acciones como ordenar, filtrar, clonar, fusionar y más.
Una vez que se realiza la entrada de sus conjuntos de datos, lo siguiente es exportarlos como archivos utilizables. La herramienta que utilice debería permitirle guardar sus conjuntos de datos en el formato que especifique para que pueda introducirlos en sus modelos de ML.
Técnicas de anotación
Para esto está construida o diseñada una herramienta de anotación de datos. Una herramienta sólida debería ofrecerle una variedad de técnicas de anotación para conjuntos de datos de todo tipo. Esto es a menos que esté desarrollando una solución personalizada para sus necesidades. Su herramienta debería permitirle anotar videos o imágenes de visión por computadora, audio o texto de PNL y transcripciones y más. Refinando esto aún más, debería haber opciones para usar cuadros delimitadores, segmentación semántica, cuboides, interpolación, análisis de sentimientos, partes del discurso, solución de correferencia y más.
Para los no iniciados, también existen herramientas de anotación de datos impulsadas por IA. Estos vienen con módulos de IA que aprenden de forma autónoma de los patrones de trabajo de un anotador y anotan automáticamente imágenes o texto. Tal
Los módulos se pueden utilizar para brindar una asistencia increíble a los anotadores, optimizar las anotaciones e incluso implementar controles de calidad.
Control de calidad de datos
Hablando de controles de calidad, varias herramientas de anotación de datos se implementan con módulos de control de calidad integrados. Estos permiten a los anotadores colaborar mejor con los miembros de su equipo y ayudan a optimizar los flujos de trabajo. Con esta función, los anotadores pueden marcar y rastrear comentarios o retroalimentación en tiempo real, rastrear las identidades detrás de las personas que realizan cambios en los archivos, restaurar versiones anteriores, optar por el consenso de etiquetado y más.
Seguridad
Dado que está trabajando con datos, la seguridad debe ser la máxima prioridad. Es posible que esté trabajando con datos confidenciales como los que involucran datos personales o propiedad intelectual. Por lo tanto, su herramienta debe proporcionar seguridad hermética en términos de dónde se almacenan los datos y cómo se comparten. Debe proporcionar herramientas que limiten el acceso a los miembros del equipo, eviten descargas no autorizadas y más.
Aparte de estos, los estándares y protocolos de seguridad deben cumplirse y cumplirse.
Gestión del personal
Una herramienta de anotación de datos también es una especie de plataforma de gestión de proyectos, donde se pueden asignar tareas a los miembros del equipo, se puede realizar trabajo colaborativo, se pueden realizar revisiones y más. Es por eso que su herramienta debe encajar en su flujo de trabajo y proceso para optimizar la productividad.
Además, la herramienta también debe tener una curva de aprendizaje mínima, ya que el proceso de anotación de datos en sí mismo requiere mucho tiempo. No sirve para nada gastar demasiado tiempo simplemente aprendiendo la herramienta. Por lo tanto, debe ser intuitivo y sin problemas para que cualquiera pueda comenzar rápidamente.
¿Cuáles son los beneficios de la anotación de datos?
La anotación de datos es crucial para optimizar los sistemas de aprendizaje automático y brindar experiencias de usuario mejoradas. Estos son algunos de los beneficios clave de la anotación de datos:
- Eficiencia de entrenamiento mejorada: El etiquetado de datos ayuda a entrenar mejor los modelos de aprendizaje automático, lo que mejora la eficiencia general y produce resultados más precisos.
- Mayor precisión: Los datos anotados con precisión garantizan que los algoritmos puedan adaptarse y aprender de manera efectiva, lo que da como resultado niveles más altos de precisión en tareas futuras.
- Intervención humana reducida: Las herramientas avanzadas de anotación de datos reducen significativamente la necesidad de intervención manual, agilizando los procesos y reduciendo los costos asociados.
Por lo tanto, la anotación de datos contribuye a sistemas de aprendizaje automático más eficientes y precisos al tiempo que minimiza los costos y el esfuerzo manual que tradicionalmente se requiere para entrenar modelos de IA.
Crear o no crear una herramienta de anotación de datos
Un problema crítico y general que puede surgir durante un proyecto de anotación o etiquetado de datos es la elección de crear o comprar funcionalidad para estos procesos. Esto puede surgir varias veces en varias fases del proyecto o estar relacionado con diferentes segmentos del programa. Al elegir si construir un sistema internamente o confiar en los proveedores, siempre hay una compensación.

Como probablemente pueda ver ahora, la anotación de datos es un proceso complejo. Al mismo tiempo, también es un proceso subjetivo. Es decir, no hay una única respuesta a la pregunta de si debería comprar o crear una herramienta de anotación de datos. Se deben considerar muchos factores y debe hacerse algunas preguntas para comprender sus requisitos y darse cuenta de si realmente necesita comprar o construir uno.
Para simplificar esto, aquí están algunos de los factores que debe considerar.
Tu meta
El primer elemento que debe definir es el objetivo con sus conceptos de inteligencia artificial y aprendizaje automático.
- ¿Por qué los está implementando en su negocio?
- ¿Resuelven un problema del mundo real al que se enfrentan sus clientes?
- ¿Están haciendo algún proceso de front-end o back-end?
- ¿Utilizará IA para introducir nuevas funciones u optimizar su sitio web, aplicación o módulo existente?
- ¿Qué está haciendo su competidor en su segmento?
- ¿Tiene suficientes casos de uso que necesitan la intervención de IA?
Las respuestas a estos recopilarán sus pensamientos, que actualmente pueden estar por todos lados, en un solo lugar y le darán más claridad.
Recolección de datos / licencias de IA
Los modelos de IA requieren solo un elemento para funcionar: los datos. Debe identificar desde dónde puede generar volúmenes masivos de datos reales. Si su empresa genera grandes volúmenes de datos que deben procesarse para obtener información crucial sobre el negocio, las operaciones, la investigación de la competencia, el análisis de la volatilidad del mercado, el estudio del comportamiento del cliente y más, necesita una herramienta de anotación de datos. Sin embargo, también debe considerar el volumen de datos que genera. Como se mencionó anteriormente, un modelo de IA es tan efectivo como la calidad y la cantidad de datos que se alimentan. Por lo tanto, sus decisiones deben depender invariablemente de este factor.
Si no tiene los datos correctos para entrenar sus modelos de ML, los proveedores pueden ser muy útiles, ayudándole con la concesión de licencias de datos del conjunto correcto de datos necesarios para entrenar modelos de ML. En algunos casos, parte del valor que aporta el proveedor implicará tanto la destreza técnica como el acceso a los recursos que promoverán el éxito del proyecto.
Presupuesto
Otra condición fundamental que probablemente influya en todos y cada uno de los factores que estamos discutiendo actualmente. La solución a la pregunta de si debe crear o comprar una anotación de datos se vuelve fácil cuando comprende si tiene suficiente presupuesto para gastar.
Complejidades de cumplimiento
 Los proveedores pueden ser de gran ayuda cuando se trata de la privacidad de los datos y el manejo correcto de los datos confidenciales. Uno de estos tipos de casos de uso involucra un hospital o una empresa relacionada con la atención médica que desea utilizar el poder del aprendizaje automático sin poner en peligro su cumplimiento con HIPAA y otras reglas de privacidad de datos. Incluso fuera del campo médico, leyes como la GDPR europea están reforzando el control de los conjuntos de datos y requieren más vigilancia por parte de las partes interesadas corporativas.
Los proveedores pueden ser de gran ayuda cuando se trata de la privacidad de los datos y el manejo correcto de los datos confidenciales. Uno de estos tipos de casos de uso involucra un hospital o una empresa relacionada con la atención médica que desea utilizar el poder del aprendizaje automático sin poner en peligro su cumplimiento con HIPAA y otras reglas de privacidad de datos. Incluso fuera del campo médico, leyes como la GDPR europea están reforzando el control de los conjuntos de datos y requieren más vigilancia por parte de las partes interesadas corporativas.
Mano de obra
La anotación de datos requiere mano de obra calificada para trabajar independientemente del tamaño, la escala y el dominio de su negocio. Incluso si está generando un mínimo de datos todos los días, necesita expertos en datos para trabajar en sus datos para el etiquetado. Entonces, ahora, debe darse cuenta de si tiene la mano de obra requerida en su lugar. Si la tiene, ¿están capacitados en las herramientas y técnicas requeridas o necesitan mejorar sus habilidades? Si necesitan mejorar sus habilidades, ¿tiene el presupuesto para capacitarlos en primer lugar?
Además, los mejores programas de anotación y etiquetado de datos toman una serie de expertos en la materia o dominio y los segmentan según datos demográficos como edad, género y área de especialización, o a menudo en términos de los idiomas localizados con los que trabajarán. Ahí es, nuevamente, donde en Shaip hablamos de conseguir que las personas adecuadas ocupen los asientos adecuados, impulsando así los procesos humanos correctos que llevarán sus esfuerzos programáticos al éxito.
Operaciones de proyectos pequeños y grandes y umbrales de costos
En muchos casos, el soporte del proveedor puede ser más una opción para un proyecto más pequeño o para fases de proyecto más pequeñas. Cuando los costos son controlables, la empresa puede beneficiarse de la subcontratación para hacer que los proyectos de anotación o etiquetado de datos sean más eficientes.
Las empresas también pueden considerar umbrales importantes, donde muchos proveedores relacionan el costo con la cantidad de datos consumidos u otros puntos de referencia de recursos. Por ejemplo, digamos que una empresa se ha registrado con un proveedor para realizar la tediosa entrada de datos necesaria para configurar los equipos de prueba.
Puede haber un umbral oculto en el acuerdo en el que, por ejemplo, el socio comercial tiene que sacar otro bloque de almacenamiento de datos de AWS, o algún otro componente de servicio de Amazon Web Services, o algún otro proveedor externo. Transmiten eso al cliente en forma de costos más altos, y pone el precio fuera del alcance del cliente.
En estos casos, medir los servicios que recibe de los proveedores ayuda a mantener el proyecto a un precio asequible. Tener el alcance correcto en su lugar asegurará que los costos del proyecto no excedan lo que es razonable o factible para la empresa en cuestión.
Alternativas de código abierto y software gratuito
 Algunas alternativas al soporte completo del proveedor implican el uso de software de código abierto, o incluso software gratuito, para realizar proyectos de anotación o etiquetado de datos. Aquí hay una especie de término medio en el que las empresas no crean todo desde cero, sino que también evitan depender demasiado de los proveedores comerciales.
Algunas alternativas al soporte completo del proveedor implican el uso de software de código abierto, o incluso software gratuito, para realizar proyectos de anotación o etiquetado de datos. Aquí hay una especie de término medio en el que las empresas no crean todo desde cero, sino que también evitan depender demasiado de los proveedores comerciales.
La mentalidad de hágalo usted mismo del código abierto es en sí misma una especie de compromiso: los ingenieros y las personas internas pueden aprovechar la comunidad de código abierto, donde las bases de usuarios descentralizadas ofrecen sus propios tipos de apoyo de base. No será como lo que obtiene de un proveedor, no obtendrá asistencia fácil las 24 horas del día, los 7 días de la semana, ni respuestas a preguntas sin realizar una investigación interna, pero el precio es más bajo.
Entonces, la gran pregunta: ¿Cuándo debería comprar una herramienta de anotación de datos?
Al igual que con muchos tipos de proyectos de alta tecnología, este tipo de análisis, cuándo construir y cuándo comprar, requiere una reflexión y una consideración dedicadas de cómo se obtienen y administran estos proyectos. Los desafíos que enfrentan la mayoría de las empresas relacionados con los proyectos de IA / ML al considerar la opción de "compilación" es que no se trata solo de las partes de construcción y desarrollo del proyecto. A menudo hay una curva de aprendizaje enorme para llegar al punto en el que puede ocurrir un verdadero desarrollo de IA / ML. Con los nuevos equipos e iniciativas de IA / ML, la cantidad de "incógnitas desconocidas" supera con creces la cantidad de "incógnitas conocidas".
| Construcción | Comprar |
|---|---|
Pros:
| Pros:
|
Contras:
| Contras:
|
Para simplificar aún más las cosas, considere los siguientes aspectos:
- cuando trabaja con grandes volúmenes de datos
- cuando trabaja con diversas variedades de datos
- cuando las funcionalidades asociadas con sus modelos o soluciones podrían cambiar o evolucionar en el futuro
- cuando tiene un caso de uso vago o genérico
- cuando necesite una idea clara de los gastos que implica la implementación de una herramienta de anotación de datos
- y cuando no tiene la fuerza laboral adecuada o los expertos calificados para trabajar en las herramientas y está buscando una curva de aprendizaje mínima
Si sus respuestas fueron opuestas a estos escenarios, debe concentrarse en construir su herramienta.
Cómo elegir la herramienta de anotación de datos adecuada para su proyecto
Si está leyendo esto, estas ideas suenan emocionantes y definitivamente son más fáciles de decir que de hacer. Entonces, ¿cómo se puede aprovechar la gran cantidad de herramientas de anotación de datos que ya existen? Entonces, el siguiente paso involucrado es considerar los factores asociados con la elección de la herramienta de anotación de datos correcta.
A diferencia de hace unos años, el mercado ha evolucionado con toneladas de herramientas de anotación de datos en la práctica hoy. Las empresas tienen más opciones para elegir una en función de sus distintas necesidades. Pero cada herramienta viene con su propio conjunto de pros y contras. Para tomar una decisión acertada, también se debe tomar una ruta objetiva al margen de los requisitos subjetivos.
Veamos algunos de los factores cruciales que debe considerar en el proceso.
Definición de su caso de uso
Para seleccionar la herramienta de anotación de datos correcta, debe definir su caso de uso. Debe saber si su requerimiento involucra texto, imagen, video, audio o una combinación de todos los tipos de datos. Existen herramientas independientes que puede comprar y existen herramientas holísticas que le permiten ejecutar diversas acciones en conjuntos de datos.
Las herramientas de hoy son intuitivas y le ofrecen opciones en términos de instalaciones de almacenamiento (red, local o en la nube), técnicas de anotación (audio, imagen, 3D y más) y una serie de otros aspectos. Puede elegir una herramienta según sus requisitos específicos.
Establecimiento de estándares de control de calidad
 Este es un factor crucial a considerar, ya que el propósito y la eficiencia de sus modelos de IA dependen de los estándares de calidad que establezca. Al igual que una auditoría, debe realizar controles de calidad de los datos que alimenta y los resultados obtenidos para comprender si sus modelos están siendo entrenados de la manera correcta y para los propósitos correctos. Sin embargo, la pregunta es ¿cómo piensa establecer estándares de calidad?
Este es un factor crucial a considerar, ya que el propósito y la eficiencia de sus modelos de IA dependen de los estándares de calidad que establezca. Al igual que una auditoría, debe realizar controles de calidad de los datos que alimenta y los resultados obtenidos para comprender si sus modelos están siendo entrenados de la manera correcta y para los propósitos correctos. Sin embargo, la pregunta es ¿cómo piensa establecer estándares de calidad?
Al igual que con muchos tipos diferentes de trabajos, muchas personas pueden realizar anotaciones y etiquetado de datos, pero lo hacen con varios grados de éxito. Cuando solicita un servicio, no verifica automáticamente el nivel de control de calidad. Por eso los resultados varían.
Entonces, ¿desea implementar un modelo de consenso, donde los anotadores ofrezcan comentarios sobre la calidad y se tomen medidas correctivas al instante? ¿O prefiere la revisión de muestras, los estándares de oro o la intersección sobre los modelos de unión?
El mejor plan de compra asegurará que el control de calidad esté en su lugar desde el principio al establecer estándares antes de que se acuerde cualquier contrato final. Al establecer esto, tampoco debe pasar por alto los márgenes de error. La intervención manual no puede evitarse por completo, ya que los sistemas están destinados a producir errores hasta en un 3%. Esto requiere trabajo por adelantado, pero vale la pena.
¿Quién anotará sus datos?
El siguiente factor importante depende de quién anota sus datos. ¿Tiene la intención de tener un equipo interno o prefiere que lo subcontraten? Si está subcontratando, existen aspectos legales y medidas de cumplimiento que debe considerar debido a las preocupaciones de privacidad y confidencialidad asociadas con los datos. Y si tiene un equipo interno, ¿qué tan eficientes son para aprender una nueva herramienta? ¿Cuál es su tiempo de comercialización con su producto o servicio? ¿Tiene las métricas de calidad y los equipos adecuados para aprobar los resultados?
El vendedor vs. Debate de socios
 La anotación de datos es un proceso colaborativo. Implica dependencias y complejidades como la interoperabilidad. Esto significa que ciertos equipos siempre están trabajando en conjunto entre sí y uno de los equipos podría ser su proveedor. Es por eso que el proveedor o socio que seleccione es tan importante como la herramienta que utiliza para el etiquetado de datos.
La anotación de datos es un proceso colaborativo. Implica dependencias y complejidades como la interoperabilidad. Esto significa que ciertos equipos siempre están trabajando en conjunto entre sí y uno de los equipos podría ser su proveedor. Es por eso que el proveedor o socio que seleccione es tan importante como la herramienta que utiliza para el etiquetado de datos.
Con este factor, se deben considerar aspectos como la capacidad de mantener sus datos e intenciones confidenciales, la intención de aceptar y trabajar en los comentarios, ser proactivo en términos de solicitudes de datos, flexibilidad en las operaciones y más antes de estrechar la mano con un proveedor o socio. . Hemos incluido flexibilidad porque los requisitos de anotación de datos no siempre son lineales o estáticos. Es posible que cambien en el futuro a medida que amplíe aún más su negocio. Si actualmente está tratando solo con datos basados en texto, es posible que desee anotar datos de audio o video a medida que escala y su soporte debe estar listo para expandir sus horizontes con usted.
Participación del proveedor
Una de las formas de evaluar la participación de los proveedores es el apoyo que recibirá.
Cualquier plan de compra debe tener en cuenta este componente. ¿Cómo se verá el soporte en el suelo? ¿Quiénes serán las partes interesadas y las personas de referencia en ambos lados de la ecuación?
También hay tareas concretas que tienen que detallar cuál es (o será) la participación del proveedor. Para un proyecto de anotación de datos o etiquetado de datos en particular, ¿el proveedor proporcionará activamente los datos sin procesar o no? ¿Quiénes actuarán como expertos en la materia y quién los empleará como empleados o como contratistas independientes?
Casos de Estudio
A continuación, se muestran algunos ejemplos de estudios de casos específicos que abordan cómo la anotación de datos y el etiquetado de datos realmente funcionan sobre el terreno. En Shaip, nos encargamos de proporcionar los más altos niveles de calidad y resultados superiores en la anotación y el etiquetado de datos.
Gran parte de la discusión anterior sobre los logros estándar para la anotación de datos y el etiquetado de datos revela cómo abordamos cada proyecto y qué ofrecemos a las empresas y partes interesadas con las que trabajamos.
Materiales de estudio de caso que demostrarán cómo funciona esto:

En un proyecto de licencia de datos clínicos, el equipo de Shaip procesó más de 6,000 horas de audio, eliminando toda la información de salud protegida (PHI) y dejando contenido compatible con HIPAA para que los modelos de reconocimiento de voz de atención médica funcionen.
En este tipo de casos, lo importante son los criterios y la clasificación de los logros. Los datos sin procesar están en forma de audio y existe la necesidad de desidentificar a las partes. Por ejemplo, al utilizar el análisis NER, el doble objetivo es desidentificar y anotar el contenido.
Otro estudio de caso implica una profunda datos de entrenamiento de IA conversacional proyecto que completamos con 3,000 lingüistas trabajando durante un período de 14 semanas. Esto llevó a la producción de datos de capacitación en 27 idiomas, con el fin de desarrollar asistentes digitales multilingües capaces de manejar interacciones humanas en una amplia selección de idiomas nativos.
En este estudio de caso en particular, fue evidente la necesidad de colocar a la persona adecuada en la silla adecuada. La gran cantidad de expertos en la materia y operadores de entrada de contenido significaba que era necesario optimizar la organización y los procedimientos para realizar el proyecto en un plazo determinado. Nuestro equipo pudo superar el estándar de la industria por un amplio margen, mediante la optimización de la recopilación de datos y los procesos posteriores.
Otros tipos de estudios de casos involucran cosas como entrenamiento de bots y anotaciones de texto para aprendizaje automático. Nuevamente, en un formato de texto, sigue siendo importante tratar a las partes identificadas de acuerdo con las leyes de privacidad y clasificar los datos sin procesar para obtener los resultados específicos.
En otras palabras, al trabajar con múltiples tipos y formatos de datos, Shaip ha demostrado el mismo éxito vital al aplicar los mismos métodos y principios a los escenarios comerciales de licencias de datos y datos sin procesar.