Introducción
 La inteligencia artificial se trata de usar máquinas para mejorar la vida y el estilo de vida de las personas al hacer que sus vidas mundanas sean interesantes y tareas redundantes simples. Nunca se supone que la IA sea una fuerza dominante, sino complementaria que trabaja en conjunto con los humanos para resolver lo inverosímil y allanar el camino para la evolución colectiva.
La inteligencia artificial se trata de usar máquinas para mejorar la vida y el estilo de vida de las personas al hacer que sus vidas mundanas sean interesantes y tareas redundantes simples. Nunca se supone que la IA sea una fuerza dominante, sino complementaria que trabaja en conjunto con los humanos para resolver lo inverosímil y allanar el camino para la evolución colectiva.
A partir de ahora, estamos avanzando por el camino correcto con importantes avances en todas las industrias con la ayuda de la inteligencia artificial. Si tomas la atención médica, por ejemplo, los sistemas de inteligencia artificial acompañados de modelos de aprendizaje automático están ayudando a los expertos a comprender mejor el cáncer y a encontrar tratamientos para él. Los trastornos neurológicos y las preocupaciones como el trastorno de estrés postraumático se tratan con la ayuda de la IA. Las vacunas se están desarrollando a un ritmo rápido gracias a las simulaciones y los ensayos clínicos impulsados por la IA.
No solo el cuidado de la salud, cada industria o segmento que toca la IA está siendo revolucionado. Los vehículos autónomos, las tiendas de conveniencia inteligentes, los dispositivos portátiles como FitBit e incluso las cámaras de nuestros teléfonos inteligentes pueden capturar mejores imágenes de nuestros rostros con IA.
Gracias a las innovaciones que se están produciendo en el espacio de la IA, las empresas están entrando en el espectro con varios casos de uso y soluciones. Debido a esto, se prevé que el mercado global de IA alcance un valor de mercado de alrededor de $ 267 mil millones para fines de 2027. Además, alrededor del 37% de las empresas ya están implementando soluciones de IA en sus procesos y productos.
Más interesante aún, cerca del 77% de los productos y servicios que usamos hoy en día funcionan con inteligencia artificial. Con el concepto de tecnología aumentando significativamente en las verticales, ¿cómo se las arreglan las empresas para hacer lo imposible con la IA?

 ¿Cómo pueden los dispositivos tan simples como un reloj predecir con precisión los ataques cardíacos en humanos? ¿Cómo es posible que los automóviles y los automóviles que siempre han requerido un conductor de repente se conviertan en conductores menos en las carreteras?
¿Cómo pueden los dispositivos tan simples como un reloj predecir con precisión los ataques cardíacos en humanos? ¿Cómo es posible que los automóviles y los automóviles que siempre han requerido un conductor de repente se conviertan en conductores menos en las carreteras?
¿Cómo nos hacen creer los chatbots que estamos hablando con otro humano del otro lado?
Si observa la respuesta a cada pregunta, se reduce a un solo elemento: DATOS. Los datos se encuentran en el centro de todas las operaciones y procesos específicos de la IA. Son los datos los que ayudan a las máquinas a comprender conceptos, procesar entradas y ofrecer resultados precisos.
Todas las principales soluciones de IA que existen son todos productos de un proceso crucial que llamamos recopilación de datos o adquisición de datos o datos de entrenamiento de IA.
Esta extensa guía tiene como objetivo ayudarlo a comprender qué es y por qué es importante.
¿Qué es la recopilación de datos de IA?
Las máquinas no tienen mente propia. La ausencia de este concepto abstracto los hace desprovistos de opiniones, hechos y capacidades como el razonamiento, la cognición y más. Son simplemente cajas o dispositivos inamovibles que ocupan espacio. Para convertirlos en medios poderosos, necesita algoritmos y, lo que es más importante, datos.
 Los algoritmos que se desarrollan necesitan algo sobre lo que trabajar y procesar, y ese algo son datos relevantes, contextuales y recientes. El proceso de recopilación de dichos datos para que las máquinas sirvan a los fines previstos se denomina recopilación de datos de IA.
Los algoritmos que se desarrollan necesitan algo sobre lo que trabajar y procesar, y ese algo son datos relevantes, contextuales y recientes. El proceso de recopilación de dichos datos para que las máquinas sirvan a los fines previstos se denomina recopilación de datos de IA.
Cada uno de los productos o soluciones habilitados para IA que utilizamos hoy en día y los resultados que ofrecen se derivan de años de capacitación, desarrollo y optimización. Desde dispositivos que ofrecen rutas de navegación hasta esos sistemas complejos que predicen fallas de equipos con días de anticipación, cada entidad ha pasado por años de capacitación en inteligencia artificial para poder entregar resultados con precisión.
Recopilación de datos de IA es el paso preliminar en el proceso de desarrollo de IA que desde el principio determina qué tan efectivo y eficiente sería un sistema de IA. Es el proceso de obtener conjuntos de datos relevantes de una miríada de fuentes lo que ayudará a los modelos de IA a procesar mejor los detalles y producir resultados significativos.




¿Cómo recopilar datos para un aprendizaje automático?
 Aquí es donde las cosas comienzan a ponerse un poco complicadas. Desde el principio, parecería que tienes una solución a un problema del mundo real en mente, sabes que la IA sería la forma ideal de hacerlo y has desarrollado tus modelos. Pero ahora, se encuentra en la fase crucial en la que necesita comenzar sus procesos de entrenamiento de IA. Necesita abundantes datos de entrenamiento de IA para que sus modelos aprendan conceptos y entreguen resultados. También necesita datos de validación para probar sus resultados y optimizar sus algoritmos.
Aquí es donde las cosas comienzan a ponerse un poco complicadas. Desde el principio, parecería que tienes una solución a un problema del mundo real en mente, sabes que la IA sería la forma ideal de hacerlo y has desarrollado tus modelos. Pero ahora, se encuentra en la fase crucial en la que necesita comenzar sus procesos de entrenamiento de IA. Necesita abundantes datos de entrenamiento de IA para que sus modelos aprendan conceptos y entreguen resultados. También necesita datos de validación para probar sus resultados y optimizar sus algoritmos.
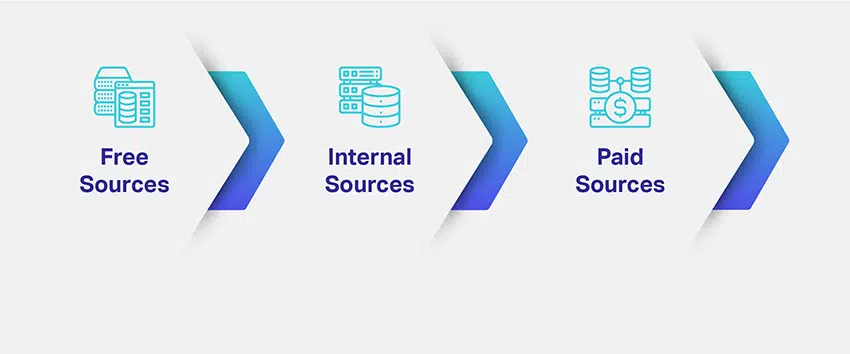
Entonces, ¿cómo obtiene sus datos? ¿Qué datos necesitas y cuántos de ellos? ¿Cuáles son las múltiples fuentes para obtener datos relevantes?
Las empresas evalúan el nicho y el propósito de sus modelos de AA y trazan formas potenciales de obtener conjuntos de datos relevantes. La definición del tipo de datos necesarios resuelve una gran parte de su preocupación sobre el suministro de datos. Para darle una mejor idea, existen diferentes canales, avenidas, fuentes o medios para la recolección de datos:
¿Cómo afectan los datos incorrectos a sus ambiciones de IA?
Enumeramos los tres recursos de datos más comunes por el motivo de que tendrá una idea sobre cómo abordar la recopilación y el abastecimiento de datos. Sin embargo, en este punto, también es esencial comprender que su decisión podría decidir invariablemente el destino de su solución de IA.
De manera similar a cómo los datos de entrenamiento de IA de alta calidad pueden ayudar a su modelo a entregar resultados precisos y oportunos, los datos de entrenamiento deficientes también pueden romper sus modelos de IA, sesgar los resultados, introducir sesgos y ofrecer otras consecuencias indeseables.
Pero, ¿por qué sucede esto? ¿No se supone que hay datos para entrenar y optimizar su modelo de IA? Honestamente no. Entendamos esto más a fondo.
Datos incorrectos: ¿qué son?
 Los datos incorrectos son cualquier dato que sea irrelevante, incorrecto, incompleto o sesgado. Gracias a estrategias de recopilación de datos mal definidas, la mayoría de los científicos de datos y expertos en anotaciones se ven obligados a trabajar con datos incorrectos.
Los datos incorrectos son cualquier dato que sea irrelevante, incorrecto, incompleto o sesgado. Gracias a estrategias de recopilación de datos mal definidas, la mayoría de los científicos de datos y expertos en anotaciones se ven obligados a trabajar con datos incorrectos.
La diferencia entre los datos no estructurados y los malos es que los conocimientos sobre los datos no estructurados están por todas partes. Pero, en esencia, podrían ser útiles independientemente. Al dedicar más tiempo, los científicos de datos aún podrían extraer información relevante de conjuntos de datos no estructurados. Sin embargo, ese no es el caso de los datos incorrectos. Estos conjuntos de datos contienen información o conocimientos limitados o nulos que sean valiosos o relevantes para su proyecto de IA o sus propósitos de capacitación.
Por lo tanto, cuando obtiene sus conjuntos de datos de recursos gratuitos o tiene puntos de contacto de datos internos poco establecidos, es muy probable que descargue o genere datos incorrectos. Cuando sus científicos trabajan con datos incorrectos, no solo está desperdiciando horas humanas, sino que también está impulsando el lanzamiento de su producto.
Si aún no tiene claro lo que los datos incorrectos pueden afectar a sus ambiciones, aquí hay una lista rápida:
- Pasas innumerables horas obteniendo datos incorrectos y desperdicias horas, esfuerzo y dinero en recursos.
- Los datos incorrectos pueden traerle problemas legales, si pasan desapercibidos y pueden reducir la eficiencia de su IA
. - Cuando lleva su producto capacitado sobre datos incorrectos en vivo, afecta la experiencia del usuario
- Los datos incorrectos podrían sesgar los resultados y las inferencias, lo que podría generar aún más reacciones negativas.
Entonces, si se pregunta si hay una solución para esto, en realidad la hay.
Proveedores de datos de entrenamiento de IA al rescate
 Una de las soluciones básicas es optar por un proveedor de datos (fuentes pagas). Los proveedores de datos de entrenamiento de IA se aseguran de que lo que recibe sea preciso y relevante y de que le entreguen conjuntos de datos en forma estructurada. No tiene que estar involucrado en las molestias de pasar de un portal a otro en busca de conjuntos de datos.
Una de las soluciones básicas es optar por un proveedor de datos (fuentes pagas). Los proveedores de datos de entrenamiento de IA se aseguran de que lo que recibe sea preciso y relevante y de que le entreguen conjuntos de datos en forma estructurada. No tiene que estar involucrado en las molestias de pasar de un portal a otro en busca de conjuntos de datos.
Todo lo que tienes que hacer es asimilar los datos y entrenar tus modelos de IA para que sean perfectos. Dicho esto, estamos seguros de que su próxima pregunta es sobre los gastos relacionados con la colaboración con los proveedores de datos. Entendemos que algunos de ustedes ya están trabajando en un presupuesto mental y eso es exactamente hacia donde nos dirigimos también.
Factores a considerar al elaborar un presupuesto efectivo para su proyecto de recopilación de datos
El entrenamiento de IA es un enfoque sistemático y es por eso que el presupuesto se convierte en una parte integral de él. Se deben considerar factores como el RoI, la precisión de los resultados, las metodologías de capacitación y más antes de invertir una gran cantidad de dinero en el desarrollo de la IA. Muchos gerentes de proyectos o dueños de negocios tienen problemas en esta etapa. Toman decisiones apresuradas que traen cambios irreversibles en su proceso de desarrollo de productos, lo que finalmente los obliga a gastar más.
Sin embargo, esta sección le brindará la información adecuada. Cuando se sienta a trabajar en el presupuesto para el entrenamiento de IA, tres cosas o factores son inevitables.

Veamos cada uno en detalle.
El volumen de datos que necesita
Hemos dicho todo el tiempo que la eficiencia y precisión de su modelo de IA depende de cuánto esté entrenado. Esto significa que cuanto mayor sea el volumen de conjuntos de datos, mayor será el aprendizaje. Pero esto es muy vago. Para poner un número a esta noción, Dimensional Research publicó un informe que reveló que las empresas necesitan un mínimo de 100,000 conjuntos de datos de muestra para entrenar sus modelos de IA.
Por 100,000 conjuntos de datos, nos referimos a 100,000 conjuntos de datos relevantes y de calidad. Estos conjuntos de datos deben tener todos los atributos, anotaciones y conocimientos esenciales necesarios para que sus algoritmos y modelos de aprendizaje automático procesen la información y ejecuten las tareas previstas.
Con esta es una regla general, entendamos mejor que el volumen de datos que necesita también depende de otro factor intrincado que es el caso de uso de su empresa. Lo que pretende hacer con su producto o solución también decide cuántos datos necesita. Por ejemplo, una empresa que crea un motor de recomendaciones tendría requisitos de volumen de datos diferentes a los de una empresa que crea un chatbot.
Estrategia de precios de datos
Cuando haya terminado de determinar la cantidad de datos que realmente necesita, debe trabajar a continuación en una estrategia de precios de datos. Esto, en términos simples, significa cómo pagaría por los conjuntos de datos que obtenga o genere.
En general, estas son las estrategias de precios convencionales que se siguen en el mercado:
| Tipo de datos | Estrategia para colocar precios |
|---|---|
| Precio por archivo de imagen individual | |
| Precio por segundo, minuto, hora o fotograma individual | |
| Precio por segundo, minuto u hora | |
| Precio por palabra u oración |
Pero espera. Esta es nuevamente una regla de oro. El costo real de adquirir conjuntos de datos también depende de factores como:
- El segmento de mercado único, la demografía o la geografía de donde se deben obtener los conjuntos de datos.
- La complejidad de su caso de uso
- ¿Cuántos datos necesitas?
- Tu tiempo para comercializar
- Cualquier requisito personalizado y más
Si observa, sabrá que el costo de adquirir grandes cantidades de imágenes para su proyecto de IA podría ser menor, pero si tiene demasiadas especificaciones, los precios podrían dispararse.
Tus estrategias de abastecimiento
Esto es complicado. Como vio, existen diferentes formas de generar o obtener datos para sus modelos de IA. El sentido común dicta que los recursos gratuitos son los mejores, ya que puede descargar los volúmenes necesarios de conjuntos de datos de forma gratuita y sin complicaciones.
En este momento, también parecería que las fuentes pagas son demasiado caras. Pero aquí es donde se agrega una capa de complicación. Cuando obtiene conjuntos de datos de recursos gratuitos, está dedicando una cantidad adicional de tiempo y esfuerzo a limpiar sus conjuntos de datos, compilarlos en el formato específico de su negocio y luego anotarlos individualmente. Está incurriendo en costos operativos en el proceso.
Con las fuentes de pago, el pago es único y también tiene a mano conjuntos de datos listos para la máquina en el momento que lo necesite. La rentabilidad es muy subjetiva aquí. Si cree que puede dedicar tiempo a anotar conjuntos de datos gratuitos, puede presupuestar en consecuencia. Y si cree que su competencia es feroz y con un tiempo de comercialización limitado, puede crear un efecto dominó en el mercado, debe preferir las fuentes pagas.
El presupuesto se trata de desglosar los detalles y definir claramente cada fragmento. Estos tres factores deberían servirle como hoja de ruta para su proceso de presupuestación de capacitación en IA en el futuro.
¿Está ahorrando en gastos con la adquisición de datos interna?
 Al presupuestar, exploramos cómo los recursos gratuitos lo obligan a gastar más a largo plazo. En ese momento, se habría preguntado automáticamente sobre la rentabilidad del proceso de adquisición de datos interno.
Al presupuestar, exploramos cómo los recursos gratuitos lo obligan a gastar más a largo plazo. En ese momento, se habría preguntado automáticamente sobre la rentabilidad del proceso de adquisición de datos interno.
Sabemos que todavía tiene dudas sobre las fuentes pagas y es por eso que esta sección aclarará su escepticismo al respecto y arrojará luz sobre los costos ocultos involucrados en la generación de datos interna.
¿Es costosa la adquisición de datos interna?
¡Sí lo es!
Ahora, aquí hay una respuesta elaborada. El gasto es todo lo que gasta. Mientras discutíamos los recursos gratuitos, revelamos que gasta dinero, tiempo y esfuerzo en el proceso. Esto también se aplica a la adquisición de datos interna.
 El hecho de que tenga puntos de contacto o embudos de datos personalizados, no significa que tenga conjuntos de datos listos para la máquina en el final. Los datos que genere seguirán siendo en su mayoría sin procesar y sin estructurar. Es posible que tenga todos los datos que necesita en un solo lugar, pero lo que contienen los datos estará por todas partes.
El hecho de que tenga puntos de contacto o embudos de datos personalizados, no significa que tenga conjuntos de datos listos para la máquina en el final. Los datos que genere seguirán siendo en su mayoría sin procesar y sin estructurar. Es posible que tenga todos los datos que necesita en un solo lugar, pero lo que contienen los datos estará por todas partes.
En última instancia, terminaría gastando en pagar a sus empleados, científicos de datos, anotadores, profesionales de control de calidad y más. También gastará en suscripciones para herramientas de anotación y
mantenimiento de CMS, CRM y otros gastos de infraestructura.
Además, es probable que los conjuntos de datos tengan problemas de sesgo y precisión, por lo que debe ordenarlos manualmente. Y si tiene un problema de desgaste en su equipo de datos de entrenamiento de IA, tendrá que gastar en reclutar nuevos miembros, orientarlos en sus procesos, capacitarlos para usar sus herramientas y más.
Terminará gastando más de lo que eventualmente ganaría a largo plazo. También hay gastos de anotación. En cualquier momento dado, el costo total incurrido para trabajar con datos internos es:
Costo incurrido = Número de anotadores * Costo por anotador + Costo de plataforma
Si su calendario de entrenamiento de IA está programado para meses, imagine los gastos en los que incurriría constantemente. Entonces, ¿es esta la solución ideal para los problemas de adquisición de datos o hay alguna alternativa?
Cómo elegir la empresa de recopilación de datos de IA adecuada
Elegir una empresa de recopilación de datos de IA no es tan complicado ni requiere tanto tiempo como recopilar datos de recursos gratuitos. Solo hay unos pocos factores simples que debe considerar y luego estrechar la mano para una colaboración.
Cuando comienza a buscar un proveedor de datos, asumimos que ha seguido y considerado todo lo que hemos discutido hasta ahora. Sin embargo, aquí hay un resumen rápido:
- Tiene un caso de uso bien definido en mente
- Su segmento de mercado y los requisitos de datos están claramente establecidos
- Tu presupuesto está a punto
- Y tienes una idea del volumen de datos que necesitas
Con estos elementos marcados, entendamos cómo puede buscar un proveedor de servicios de datos de entrenamiento ideal.