
La IA, los macrodatos y el aprendizaje automático siguen influyendo en los responsables políticos, las empresas, la ciencia, los medios de comunicación y una variedad de industrias en todo el mundo. Los informes sugieren que la tasa de adopción global de IA se encuentra actualmente en 35% en 2022 – un enorme aumento del 4% a partir de 2021. Según se informa, un 42% adicional de las empresas están explorando los muchos beneficios de la IA para sus negocios.
Impulsando las muchas iniciativas de IA y Aprendizaje automático (Machine learning & LLM) soluciones son datos. La IA solo puede ser tan buena como los datos que alimentan el algoritmo. Los datos de baja calidad podrían generar resultados de baja calidad y predicciones inexactas.
Si bien se ha prestado mucha atención al desarrollo de soluciones de ML e IA, falta la conciencia de lo que califica como un conjunto de datos de calidad. En este artículo, navegamos por la línea de tiempo de datos de entrenamiento de IA de calidad e identificar el futuro de la IA a través de la comprensión de la recopilación de datos y la capacitación.
Definición de datos de entrenamiento de IA
Al crear una solución de ML, la cantidad y la calidad del conjunto de datos de entrenamiento son importantes. El sistema ML no solo requiere grandes volúmenes de datos de entrenamiento dinámicos, imparciales y valiosos, sino que también necesita muchos.
Pero, ¿qué son los datos de entrenamiento de IA?
Los datos de entrenamiento de IA son una colección de datos etiquetados que se utilizan para entrenar el algoritmo ML para hacer predicciones precisas. El sistema ML intenta reconocer e identificar patrones, comprender las relaciones entre parámetros, tomar las decisiones necesarias y evaluar en función de los datos de entrenamiento.
Tomemos el ejemplo de los autos sin conductor, por ejemplo. El conjunto de datos de entrenamiento para un modelo de aprendizaje automático autónomo debe incluir imágenes y videos etiquetados de automóviles, peatones, letreros de calles y otros vehículos.
En resumen, para mejorar la calidad del algoritmo ML, necesita grandes cantidades de datos de entrenamiento bien estructurados, anotados y etiquetados.
Importancia de la calidad de los datos de entrenamiento y su Evolución
Los datos de entrenamiento de alta calidad son la entrada clave en el desarrollo de aplicaciones de IA y ML. Los datos se recopilan de varias fuentes y se presentan en una forma no organizada que no es adecuada para fines de aprendizaje automático. Los datos de entrenamiento de calidad (etiquetados, anotados y etiquetados) siempre están en un formato organizado, ideal para el entrenamiento de ML.
Los datos de entrenamiento de calidad facilitan que el sistema ML reconozca objetos y los clasifique de acuerdo con características predeterminadas. El conjunto de datos podría generar malos resultados del modelo si la clasificación no es precisa.
Los primeros días de los datos de entrenamiento de IA
A pesar de que la IA domina el mundo actual de los negocios y la investigación, los primeros días antes de que ML dominara Inteligencia artificial era bastante diferente.
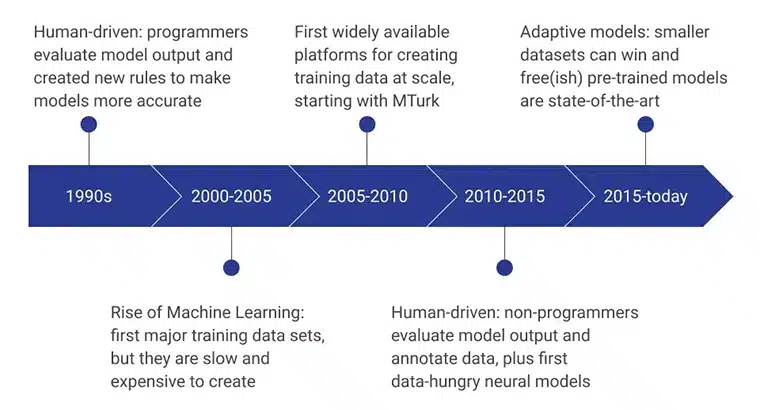
Las etapas iniciales de los datos de entrenamiento de IA fueron impulsadas por programadores humanos que evaluaron el resultado del modelo al idear constantemente nuevas reglas que hicieron que el modelo fuera más eficiente. En el período 2000-2005, se creó el primer conjunto de datos importante y fue un proceso extremadamente lento, costoso y que dependía de los recursos. Condujo al desarrollo de conjuntos de datos de capacitación a escala, y MTurk de Amazon desempeñó un papel importante en el cambio de las percepciones de las personas sobre la recopilación de datos. Simultáneamente, el etiquetado y la anotación humanos también despegaron.
Los siguientes años se centraron en que los no programadores crearan y evaluaran los modelos de datos. Actualmente, la atención se centra en modelos preentrenados desarrollados utilizando métodos avanzados de recopilación de datos de entrenamiento.
Cantidad sobre calidad
Al evaluar la integridad de los conjuntos de datos de entrenamiento de IA en el pasado, los científicos de datos se centraron en Cantidad de datos de entrenamiento de IA sobre la calidad.
Por ejemplo, había una idea errónea común de que las grandes bases de datos brindan resultados precisos. Se creía que el gran volumen de datos era un buen indicador del valor de los datos. La cantidad es solo uno de los factores principales que determinan el valor del conjunto de datos: se reconoció el papel de la calidad de los datos.
La conciencia de que calidad de los datos dependía de la integridad, confiabilidad, validez, disponibilidad y oportunidad de los datos aumentada. Lo que es más importante, la idoneidad de los datos para el proyecto determinó la calidad de los datos recopilados.
Limitaciones de los primeros sistemas de IA debido a datos de entrenamiento deficientes
Los datos de entrenamiento deficientes, junto con la falta de sistemas informáticos avanzados, fueron una de las razones de varias promesas incumplidas de los primeros sistemas de IA.
Debido a la falta de datos de entrenamiento de calidad, las soluciones de ML no pudieron identificar con precisión los patrones visuales, lo que detuvo el desarrollo de la investigación neuronal. Aunque muchos investigadores identificaron la promesa del reconocimiento del lenguaje hablado, la investigación o el desarrollo de herramientas de reconocimiento del habla no pudieron concretarse debido a la falta de conjuntos de datos del habla. Otro obstáculo importante para el desarrollo de herramientas de inteligencia artificial de alta gama fue la falta de capacidades computacionales y de almacenamiento de las computadoras.
El cambio a datos de capacitación de calidad
Hubo un cambio marcado en la conciencia de que la calidad del conjunto de datos es importante. Para que el sistema ML imite con precisión la inteligencia humana y las capacidades de toma de decisiones, debe prosperar con datos de entrenamiento de gran volumen y alta calidad.
Piense en sus datos de ML como una encuesta: cuanto más grande sea muestra de datos tamaño, mejor será la predicción. Si los datos de muestra no incluyen todas las variables, es posible que no reconozca patrones o arroje conclusiones inexactas.
Avances en la tecnología de IA y la necesidad de mejores datos de entrenamiento
 Los avances en la tecnología de IA aumentan la necesidad de datos de entrenamiento de calidad.
Los avances en la tecnología de IA aumentan la necesidad de datos de entrenamiento de calidad.La comprensión de que mejores datos de entrenamiento aumentan la posibilidad de modelos ML confiables dio lugar a mejores metodologías de recopilación, anotación y etiquetado de datos. La calidad y la relevancia de los datos afectaron directamente la calidad del modelo de IA.
 Los avances en la tecnología de IA aumentan la necesidad de datos de entrenamiento de calidad.
Los avances en la tecnología de IA aumentan la necesidad de datos de entrenamiento de calidad.Mayor atención a la calidad y precisión de los datos
Para que el modelo ML comience a proporcionar resultados precisos, se alimenta de conjuntos de datos de calidad que pasan por pasos iterativos de refinamiento de datos.
Por ejemplo, un ser humano podría reconocer una raza de perro específica unos días después de haber sido presentado a la raza, a través de imágenes, videos o en persona. Los seres humanos extraen de su experiencia e información relacionada para recordar y extraer este conocimiento cuando sea necesario. Sin embargo, no funciona tan fácilmente para una Máquina. La máquina debe alimentarse con imágenes claramente anotadas y etiquetadas (cientos o miles) de esa raza en particular y otras razas para que pueda hacer la conexión.
Un modelo de IA predice el resultado al correlacionar la información entrenada con la información presentada en el mundo real. El algoritmo se vuelve inútil si los datos de entrenamiento no incluyen información relevante.
Importancia de datos de entrenamiento diversos y representativos
Una mayor diversidad de datos también aumenta la competencia, reduce el sesgo y aumenta la representación equitativa de todos los escenarios. Si el modelo de IA se entrena con un conjunto de datos homogéneo, puede estar seguro de que la nueva aplicación funcionará solo para un propósito específico y atenderá a una población específica.Un conjunto de datos podría estar sesgado hacia una población, raza, género, elección y opiniones intelectuales en particular, lo que podría conducir a un modelo inexacto.
Es importante garantizar que todo el flujo del proceso de recopilación de datos, incluida la selección del grupo de sujetos, la curación, la anotación y el etiquetado, sea adecuadamente diverso, equilibrado y representativo de la población.
 Una mayor diversidad de datos también aumenta la competencia, reduce el sesgo y aumenta la representación equitativa de todos los escenarios. Si el modelo de IA se entrena con un conjunto de datos homogéneo, puede estar seguro de que la nueva aplicación funcionará solo para un propósito específico y atenderá a una población específica.
Una mayor diversidad de datos también aumenta la competencia, reduce el sesgo y aumenta la representación equitativa de todos los escenarios. Si el modelo de IA se entrena con un conjunto de datos homogéneo, puede estar seguro de que la nueva aplicación funcionará solo para un propósito específico y atenderá a una población específica.El futuro de los datos de entrenamiento de IA
El éxito futuro de los modelos de IA depende de la calidad y la cantidad de datos de entrenamiento utilizados para entrenar los algoritmos de ML. Es fundamental reconocer que esta relación entre la calidad y la cantidad de datos es específica de la tarea y no tiene una respuesta definitiva.
En última instancia, la idoneidad de un conjunto de datos de entrenamiento se define por su capacidad para funcionar bien de manera confiable para el propósito para el que se creó.
Avances en las técnicas de recopilación y anotación de datos
Dado que ML es sensible a los datos alimentados, es vital optimizar las políticas de recopilación y anotación de datos. Los errores en la recopilación de datos, la conservación, la tergiversación, las mediciones incompletas, el contenido inexacto, la duplicación de datos y las mediciones erróneas contribuyen a una calidad de datos insuficiente.
La recopilación de datos automatizada a través de la minería de datos, el web scraping y la extracción de datos está allanando el camino para una generación de datos más rápida. Además, los conjuntos de datos preempaquetados actúan como una técnica de recopilación de datos de solución rápida.
El crowdsourcing es otro método innovador de recopilación de datos. Si bien no se puede garantizar la veracidad de los datos, es una excelente herramienta para recopilar una imagen pública. Por último, especializado la recopilación de datos los expertos también proporcionan datos obtenidos para propósitos específicos.
Mayor énfasis en las consideraciones éticas en los datos de entrenamiento
Con los rápidos avances en IA, han surgido varios problemas éticos, especialmente en la recopilación de datos de capacitación. Algunas consideraciones éticas en la recopilación de datos de capacitación incluyen el consentimiento informado, la transparencia, el sesgo y la privacidad de los datos.Dado que los datos ahora incluyen de todo, desde imágenes faciales, huellas dactilares, grabaciones de voz y otros datos biométricos críticos, es cada vez más importante garantizar el cumplimiento de las prácticas legales y éticas para evitar juicios costosos y daños a la reputación.
El potencial de una calidad aún mejor y datos de entrenamiento diversos en el futuro
Hay un enorme potencial para datos de entrenamiento variados y de alta calidad en el futuro. Gracias a la conciencia de la calidad de los datos y la disponibilidad de proveedores de datos que atienden las demandas de calidad de las soluciones de IA.
Los proveedores de datos actuales son expertos en el uso de tecnologías innovadoras para obtener cantidades masivas de diversos conjuntos de datos de manera ética y legal. También cuentan con equipos internos para etiquetar, anotar y presentar los datos personalizados para diferentes proyectos de ML.
 Con los rápidos avances en IA, han surgido varios problemas éticos, especialmente en la recopilación de datos de capacitación. Algunas consideraciones éticas en la recopilación de datos de capacitación incluyen el consentimiento informado, la transparencia, el sesgo y la privacidad de los datos.
Con los rápidos avances en IA, han surgido varios problemas éticos, especialmente en la recopilación de datos de capacitación. Algunas consideraciones éticas en la recopilación de datos de capacitación incluyen el consentimiento informado, la transparencia, el sesgo y la privacidad de los datos.Conclusión
Es importante asociarse con proveedores confiables con una gran comprensión de los datos y la calidad para desarrollar modelos de IA de gama alta. Shaip es la principal empresa de anotaciones experta en proporcionar soluciones de datos personalizadas que satisfacen las necesidades y los objetivos de su proyecto de IA. Asóciese con nosotros y explore las competencias, el compromiso y la colaboración que ponemos sobre la mesa.


