
La Inteligencia Artificial y Big Data tienen el potencial de encontrar soluciones a problemas globales al tiempo que priorizan los problemas locales y transforman el mundo de muchas maneras profundas. La IA brinda soluciones para todos, y en todos los entornos, desde los hogares hasta los lugares de trabajo. computadoras de IA, con Aprendizaje automático (Machine learning & LLM) entrenamiento, puede simular comportamiento inteligente y conversaciones de manera automatizada pero personalizada.
Sin embargo, la IA se enfrenta a un problema de inclusión y, a menudo, está sesgada. Afortunadamente, centrándose en ética de la inteligencia artificial puede marcar el comienzo de nuevas posibilidades en términos de diversificación e inclusión al eliminar el sesgo inconsciente a través de diversos datos de capacitación.
Importancia de la diversidad en los datos de entrenamiento de IA
 La diversidad y la calidad de los datos de entrenamiento están relacionadas, ya que uno afecta al otro e impacta el resultado de la solución de IA. El éxito de la solución de IA depende de la datos diversos está entrenado. La diversidad de datos evita que la IA se sobreajuste, lo que significa que el modelo solo funciona o aprende de los datos utilizados para entrenar. Con el sobreajuste, el modelo de IA no puede proporcionar resultados cuando se prueba con datos que no se usan en el entrenamiento.
La diversidad y la calidad de los datos de entrenamiento están relacionadas, ya que uno afecta al otro e impacta el resultado de la solución de IA. El éxito de la solución de IA depende de la datos diversos está entrenado. La diversidad de datos evita que la IA se sobreajuste, lo que significa que el modelo solo funciona o aprende de los datos utilizados para entrenar. Con el sobreajuste, el modelo de IA no puede proporcionar resultados cuando se prueba con datos que no se usan en el entrenamiento.
El estado actual del entrenamiento en IA datos
La desigualdad o falta de diversidad en los datos conduciría a soluciones de IA injustas, poco éticas y no inclusivas que podrían profundizar la discriminación. Pero, ¿cómo y por qué se relaciona la diversidad de datos con las soluciones de IA?
La representación desigual de todas las clases conduce a la identificación errónea de rostros; un caso importante es Google Photos, que clasificó a una pareja negra como 'gorilas'. Y Meta le pregunta a un usuario que ve un video de hombres negros si le gustaría "seguir viendo videos de primates".
Por ejemplo, la clasificación inexacta o incorrecta de las minorías étnicas o raciales, especialmente en los chatbots, podría generar prejuicios en los sistemas de capacitación de IA. Según el informe de 2019 sobre Sistemas discriminatorios: género, raza, poder en IA, más del 80% de los docentes de IA son hombres; las investigadoras de IA en FB constituyen solo el 15% y el 10% en Google.
El impacto de diversos datos de entrenamiento en el rendimiento de la IA
 Omitir grupos y comunidades específicos de la representación de datos puede conducir a algoritmos sesgados.
Omitir grupos y comunidades específicos de la representación de datos puede conducir a algoritmos sesgados.
El sesgo de datos a menudo se introduce accidentalmente en los sistemas de datos, al submuestrear ciertas razas o grupos. Cuando los sistemas de reconocimiento facial se entrenan en diversos rostros, ayudan al modelo a identificar características específicas, como la posición de los órganos faciales y las variaciones de color.
Otro resultado de tener una frecuencia de etiquetas desequilibrada es que el sistema puede considerar una minoría como una anomalía cuando se le presiona para producir una salida en poco tiempo.
Lograr la diversidad en los datos de entrenamiento de IA
Por otro lado, generar un conjunto de datos diverso también es un desafío. La pura falta de datos sobre ciertas clases podría conducir a una subrepresentación. Se puede mitigar haciendo que los equipos de desarrolladores de IA sean más diversos con respecto a las habilidades, el origen étnico, la raza, el género, la disciplina y más. Además, la forma ideal de abordar los problemas de diversidad de datos en la IA es confrontarlos desde el principio en lugar de tratar de arreglar lo que se hizo, infundiendo diversidad en la etapa de recopilación y curación de datos.
Independientemente de la exageración en torno a la IA, todavía depende de los datos recopilados, seleccionados y entrenados por humanos. El sesgo innato en los humanos se reflejará en los datos recopilados por ellos, y este sesgo inconsciente también se infiltra en los modelos ML.
Pasos para recopilar y seleccionar diversos datos de capacitación
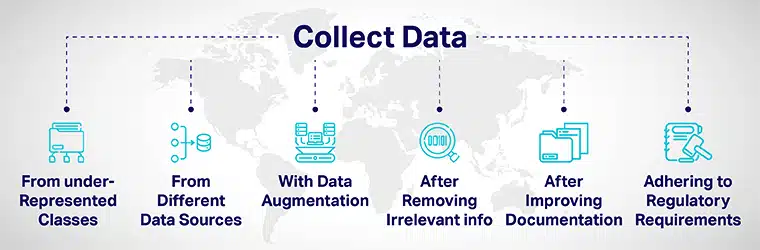
Diversidad de datos se puede lograr mediante:
- Agregue cuidadosamente más datos de clases subrepresentadas y exponga sus modelos a puntos de datos variados.
- Mediante la recopilación de datos de diferentes fuentes de datos.
- Mediante el aumento de datos o la manipulación artificial de conjuntos de datos para aumentar/incluir nuevos puntos de datos claramente diferentes de los puntos de datos originales.
- Al contratar candidatos para el proceso de desarrollo de IA, elimine toda la información irrelevante para el trabajo de la solicitud.
- Mejorar la transparencia y la rendición de cuentas mediante la mejora de la documentación del desarrollo y la evaluación de modelos.
- Introducir normas para construir diversidad y inclusión en IA sistemas desde el nivel de base. Varios gobiernos han desarrollado pautas para garantizar la diversidad y mitigar el sesgo de la IA que puede generar resultados injustos.
[ Lea también: Más información sobre el proceso de recopilación de datos de entrenamiento de IA ]
Conclusión
En la actualidad, solo unas pocas grandes empresas de tecnología y centros de aprendizaje participan exclusivamente en el desarrollo de soluciones de IA. Estos espacios de élite están impregnados de exclusión, discriminación y prejuicios. Sin embargo, estos son los espacios donde se está desarrollando la IA, y la lógica detrás de estos sistemas avanzados de IA está repleta del mismo sesgo, discriminación y exclusión que tienen los grupos subrepresentados.
Al discutir la diversidad y la no discriminación, es importante cuestionar a las personas a las que beneficia y a las que perjudica. También deberíamos analizar a quién pone en desventaja: al forzar la idea de una persona "normal", la IA podría poner en riesgo a "otros".
Discutir la diversidad en los datos de IA sin reconocer las relaciones de poder, la equidad y la justicia no mostrará el panorama general. Para comprender completamente el alcance de la diversidad en los datos de entrenamiento de IA y cómo los humanos y la IA juntos pueden mitigar esta crisis, Comuníquese con los ingenieros de Shaip. Contamos con diversos ingenieros de IA que pueden proporcionar datos dinámicos y diversos para sus soluciones de IA.


