La inteligencia artificial está revolucionando la industria de la música, ofreciendo herramientas automatizadas de composición, masterización e interpretación. Los algoritmos de IA generan composiciones novedosas, predicen éxitos y personalizan la experiencia del oyente, transformando la producción, distribución y consumo de música. Esta tecnología emergente presenta oportunidades emocionantes y dilemas éticos desafiantes.
Los modelos de aprendizaje automático (ML) requieren datos de entrenamiento para funcionar de manera efectiva, ya que un compositor necesita notas musicales para escribir una sinfonía. En el mundo de la música, donde la melodía, el ritmo y la emoción se entrelazan, no se puede subestimar la importancia de los datos de entrenamiento de calidad. Es la columna vertebral del desarrollo de modelos de aprendizaje automático de música robustos y precisos para el análisis predictivo, la clasificación de géneros o la transcripción automática.
Datos, el elemento vital de los modelos de ML
El aprendizaje automático está inherentemente basado en datos. Estos modelos computacionales aprenden patrones de los datos, lo que les permite hacer predicciones o tomar decisiones. Para los modelos de aprendizaje automático de música, los datos de entrenamiento a menudo vienen en pistas de música digitalizadas, letras, metadatos o una combinación de estos elementos. La calidad, cantidad y diversidad de estos datos impactan significativamente en la efectividad del modelo.

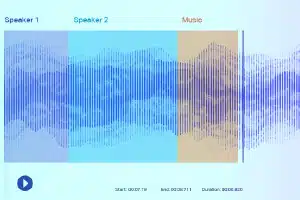
Etiquetado de sonido
Con el etiquetado de sonido, los anotadores de datos reciben una grabación y deben separar todos los sonidos necesarios y etiquetarlos. Por ejemplo, pueden ser ciertas palabras clave o el sonido de un instrumento musical específico.

Clasificación de música
Los anotadores de datos pueden marcar géneros o instrumentos en este tipo de anotación de audio. La clasificación de música es muy útil para organizar bibliotecas de música y mejorar las recomendaciones de los usuarios.

Segmentación de nivel fonético
Etiquetado y clasificación de segmentos fonéticos en las formas de onda y espectrogramas de grabaciones de individuos cantando acapella.
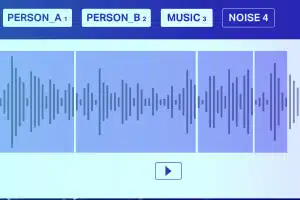
Clasificación de sonido
A excepción del silencio/ruido blanco, un archivo de audio generalmente consta de los siguientes tipos de sonido: Habla, Balbuceo, Música y Ruido. Anote con precisión las notas musicales para una mayor precisión.
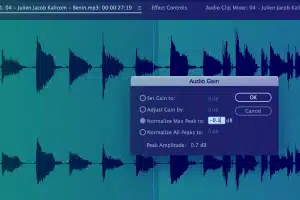
Captura de información de metadatos
Capture información importante, como la hora de inicio, la hora de finalización, la identificación del segmento, el nivel de volumen, el tipo de sonido principal, el código de idioma, la identificación del hablante y otras convenciones de transcripción, etc.